Compression
Introduction
HTTP compression is a technique that allows you to encode information using fewer bits than the original representation. When used for delivering web content, it enables web servers to reduce the amount of data transmitted to clients. This increases the efficiency of the client’s available bandwidth, reduces page weight, and improves web performance.
Compression algorithms are often categorized as lossy or lossless:
- When a lossy compression algorithm is used, the process is irreversible, and the original file cannot be restored via decompression. This is commonly used to compress media resources, such as image and video content where losing some data will not materially affect the resource.
- Lossless compression is a completely reversible process, and is commonly used to compress text based resources, such as HTML, JavaScript, CSS, etc.
In this chapter, we are going to explore how text-based content is compressed on the web. Analysis of non-text-based content forms part of the Media chapter.
How HTTP compression works
When a client makes an HTTP request, it often includes an Accept-Encoding header to advertise the compression algorithms it is capable of decoding. The server can then select from one of the advertised encodings it supports and serve a compressed response. The compressed response would include a Content-Encoding header so that the client is aware of which compression was used. Additionally, a Content-Type header is often used to indicate the MIME type of the resource being served.
In the example below, the client advertised support for Gzip, Brotli, and Deflate compression. The server decided to return a Gzip compressed response containing a text/html document.
> GET / HTTP/1.1
> Host: httparchive.org
> Accept-Encoding: gzip, deflate, br
< HTTP/1.1 200
< Content-type: text/html; charset=utf-8
< Content-encoding: gzipThe HTTP Archive contains measurements for 5.3 million web sites, and each site loaded at least 1 compressed text resource on their home page. Additionally, resources were compressed on the primary domain on 81% of web sites.
Compression algorithms
IANA maintains a list of valid HTTP content encodings that can be used with the Accept-Encoding and Content-Encoding headers. These include gzip, deflate, br (Brotli), as well as a few others. Brief descriptions of these algorithms are given below:
- Gzip uses the LZ77 and Huffman coding compression techniques, and is older than the web itself. It was originally developed for the UNIX
gzipprogram in 1992. An implementation for web delivery has existed since HTTP/1.1, and most web browsers and clients support it. - Deflate uses the same algorithm as Gzip, just with a different container. Its use was not widely adopted for the web because of compatibility issues with some servers and browsers.
- Brotli is a newer compression algorithm that was invented by Google. It uses the combination of a modern variant of the LZ77 algorithm, Huffman coding, and second order context modeling. Compression via Brotli is more computationally expensive compared to Gzip, but the algorithm is able to reduce files by 15-25% more than Gzip compression. Brotli was first used for compressing web content in 2015 and is supported by all modern web browsers.
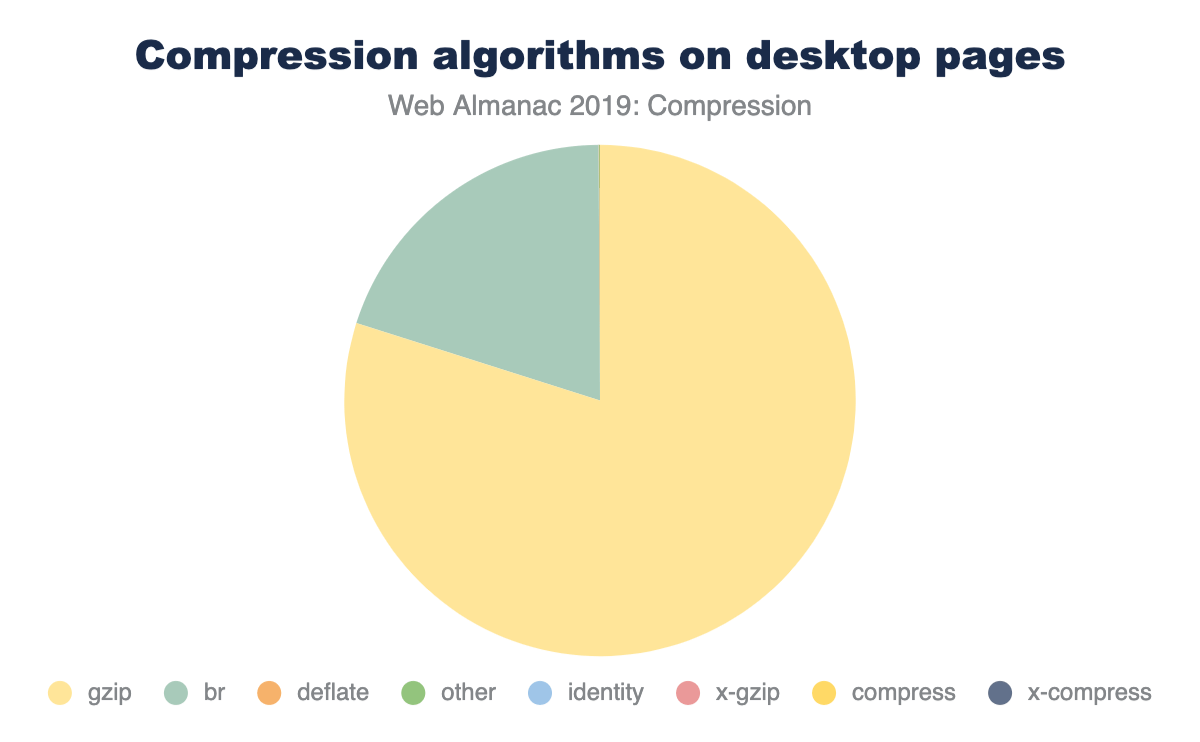
Approximately 38% of HTTP responses are delivered with text-based compression. This may seem like a surprising statistic, but keep in mind that it is based on all HTTP requests in the dataset. Some content, such as images, will not benefit from these compression algorithms. The table below summarizes the percentage of requests served with each content encoding.
| Percent of Requests | Requests | |||
|---|---|---|---|---|
| Content Encoding | Desktop | Mobile | Desktop | Mobile |
| No Text Compression | 62.87% | 61.47% | 260,245,106 | 285,158,644 |
gzip |
29.66% | 30.95% | 122,789,094 | 143,549,122 |
br |
7.43% | 7.55% | 30,750,681 | 35,012,368 |
deflate |
0.02% | 0.02% | 68,802 | 70,679 |
| Other / Invalid | 0.02% | 0.01% | 67,527 | 68,352 |
identity |
0.000709% | 0.000563% | 2,935 | 2,611 |
x-gzip |
0.000193% | 0.000179% | 800 | 829 |
compress |
0.000008% | 0.000007% | 33 | 32 |
x-compress |
0.000002% | 0.000006% | 8 | 29 |
Of the resources that are served compressed, the majority are using either Gzip (80%) or Brotli (20%). The other compression algorithms are infrequently used.
Additionally, there are 67k requests that return an invalid Content-Encoding, such as “none”, “UTF-8”, “base64”, “text”, etc. These resources are likely served uncompressed.
We can’t determine the compression levels from any of the diagnostics collected by the HTTP Archive, but the best practice for compressing content is:
- At a minimum, enable Gzip compression level 6 for text based assets. This provides a fair trade-off between computational cost and compression ratio and is the default for many web servers—though Nginx still defaults to the, often too low, level 1.
- If you can support Brotli and precompress resources, then compress to Brotli level 11. This is more computationally expensive than Gzip - so precompression is an absolute must to avoid delays.
- If you can support Brotli and are unable to precompress, then compress to Brotli level 5. This level will result in smaller payloads compared to Gzip, with a similar computational overhead.
What types of content are we compressing?
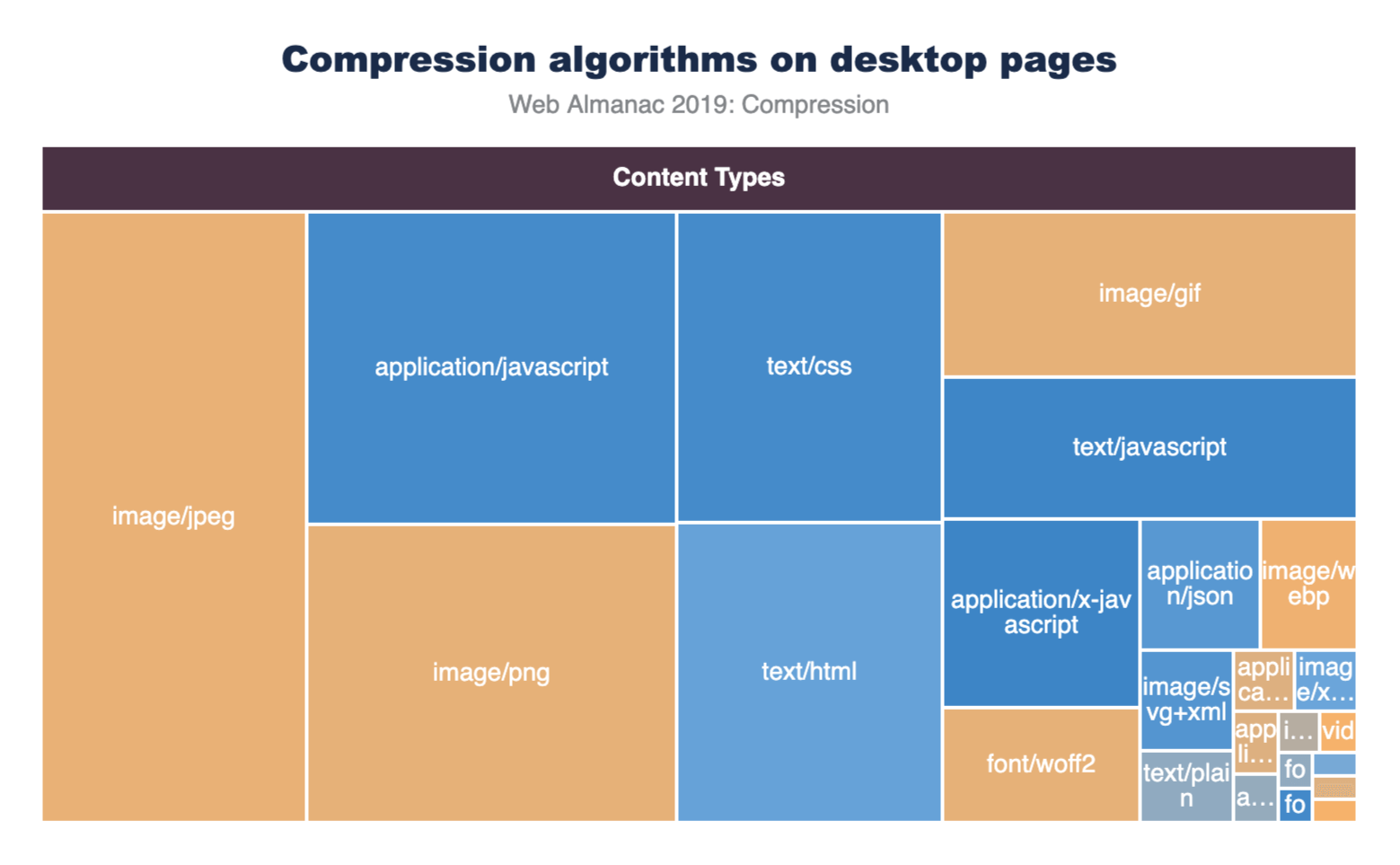
Most text based resources (such as HTML, CSS, and JavaScript) can benefit from Gzip or Brotli compression. However, it’s often not necessary to use these compression techniques on binary resources, such as images, video, and some web fonts because their file formats are already compressed.
In the graph below, the top 25 content types are displayed with box sizes representing the relative number of requests. The color of each box represents how many of these resources were served compressed. Most of the media content is shaded orange, which is expected since Gzip and Brotli would have little to no benefit for them. Most of the text content is shaded blue to indicate that they are being compressed. However, the light blue shading for some content types indicate that they are not compressed as consistently as the others.
Filtering out the eight most popular content types allows us to see the compression stats for the rest of these content types more clearly.
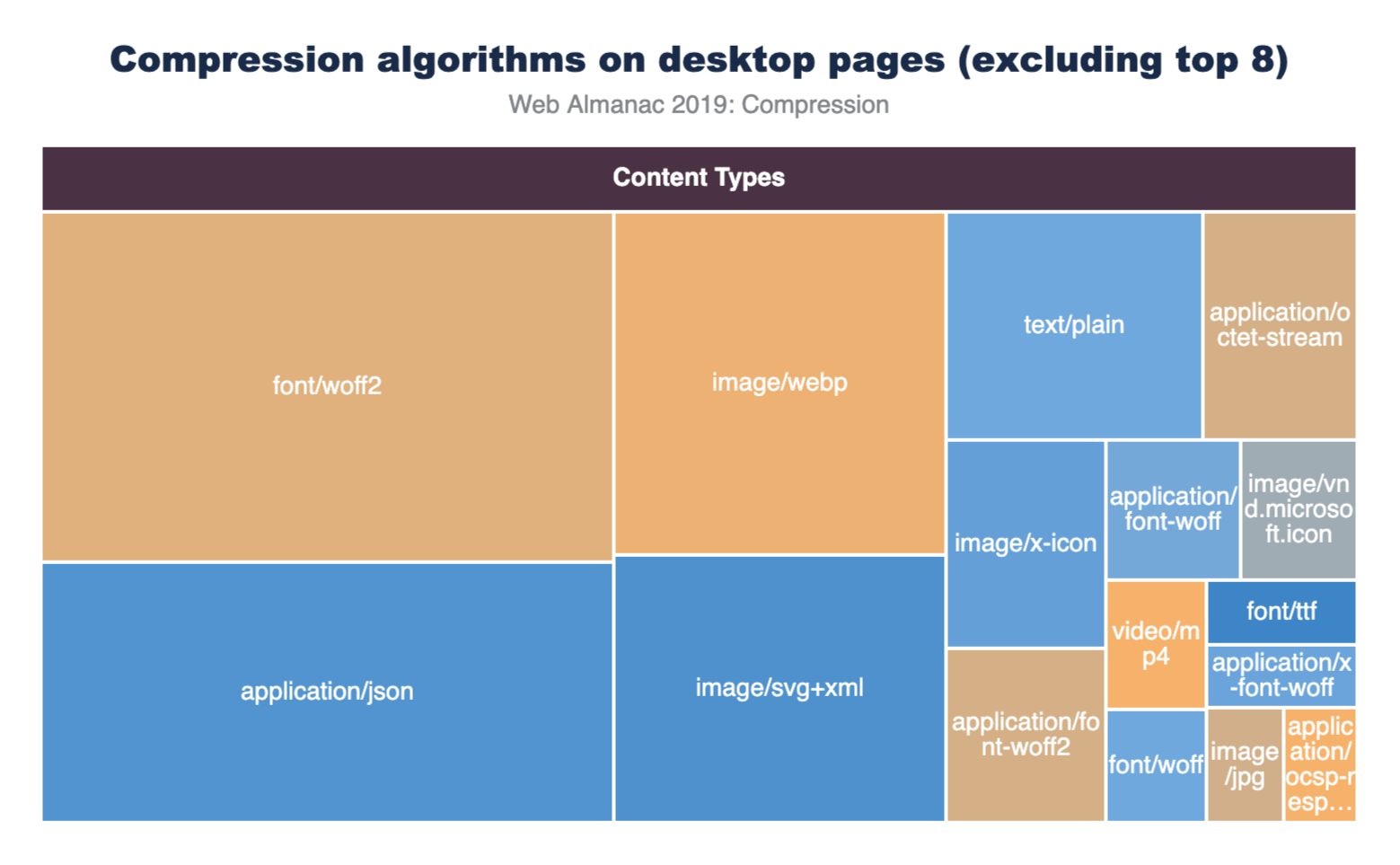
The application/json and image/svg+xml content types are compressed less than 65% of the time.
Most of the custom web fonts are served without compression, since they are already in a compressed format. However, font/ttf is compressible, but only 84% of TTF font requests are being served with compression so there is still room for improvement here.
The graphs below illustrate the breakdown of compression techniques used for each content type. Looking at the top three content types, we can see that across both desktop and mobile there are major gaps in compressing some of the most frequently requested content types. 56% of text/html as well as 18% of application/javascript and text/css resources are not being compressed. This presents a significant performance opportunity.
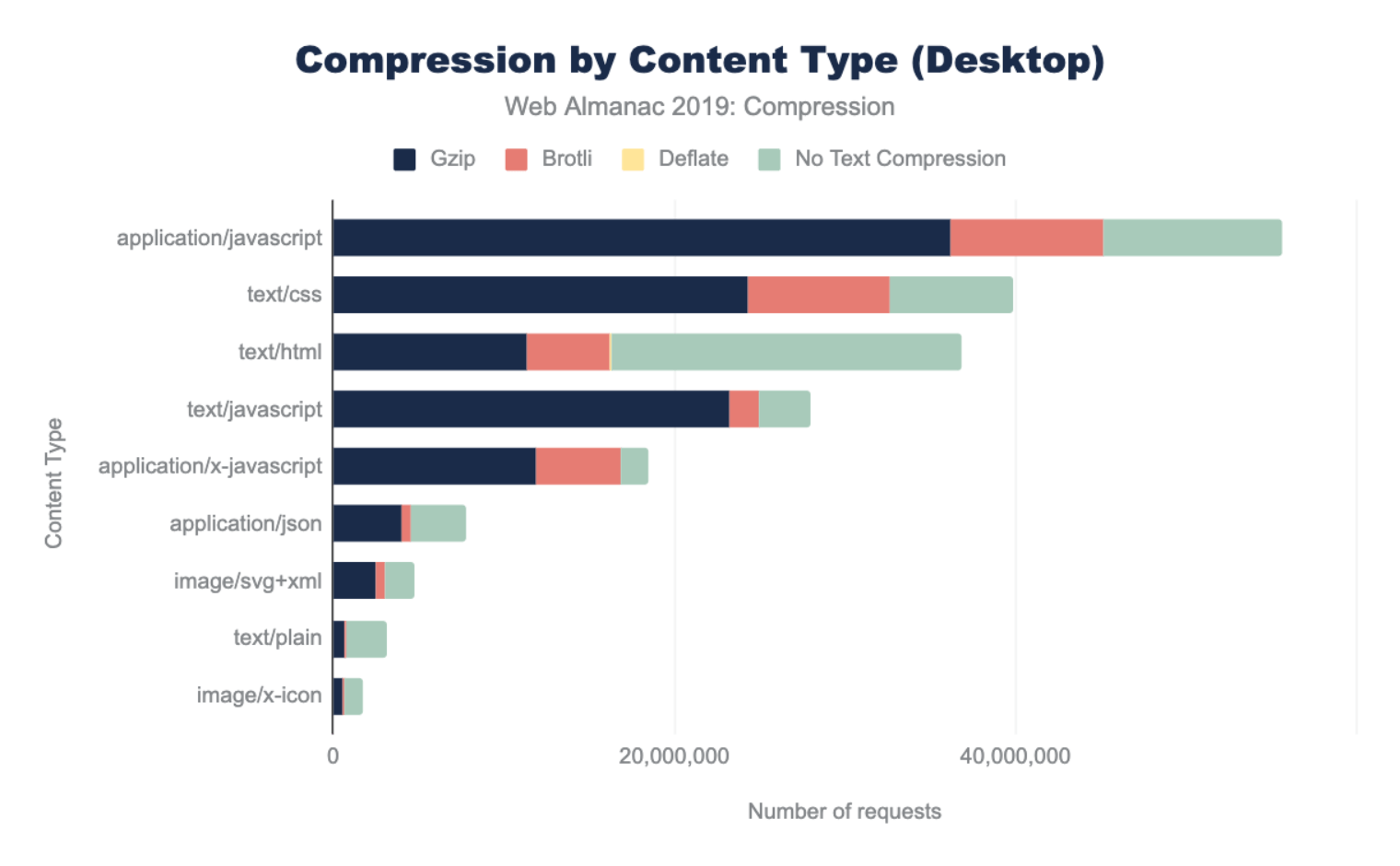
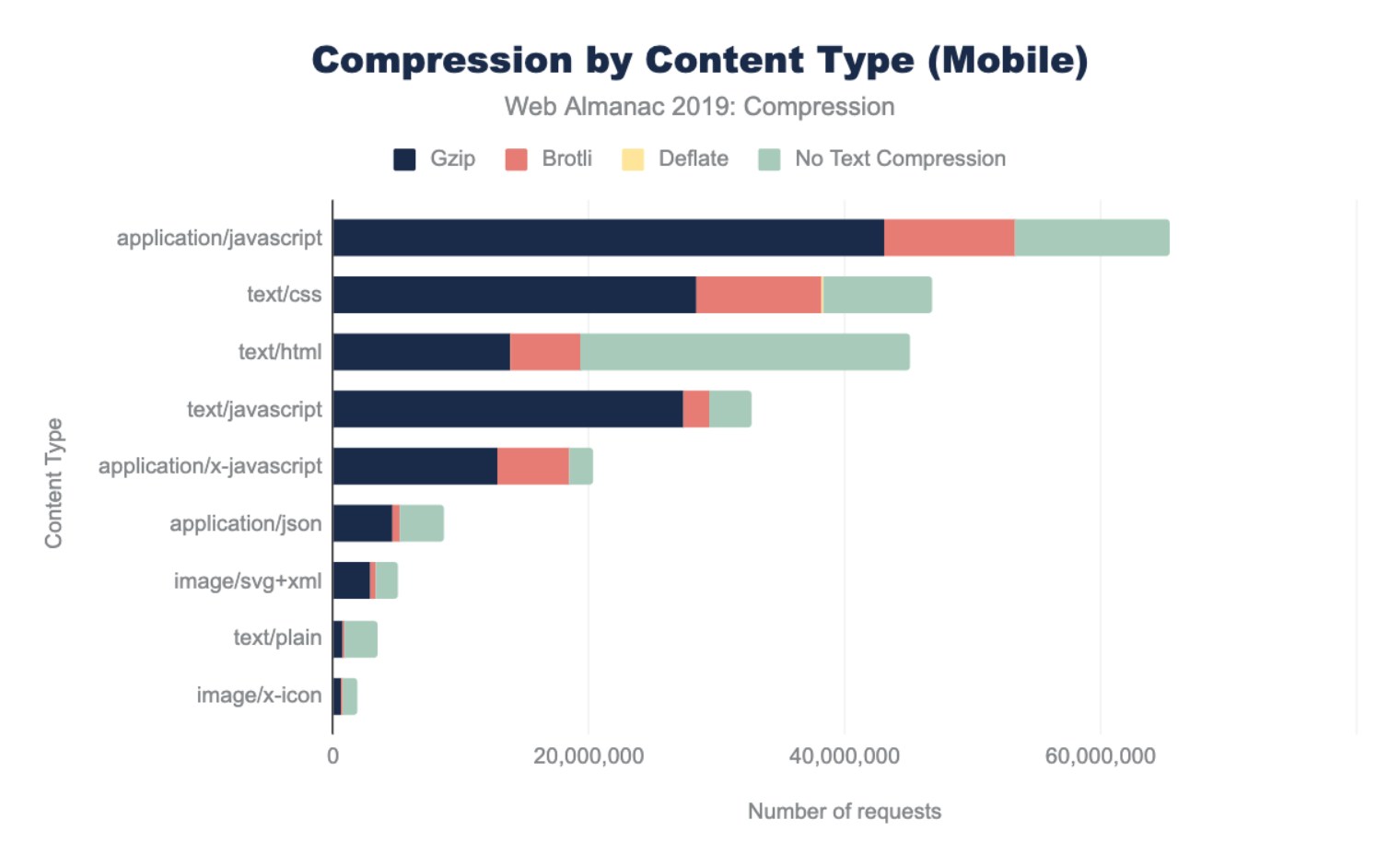
The content types with the lowest compression rates include application/json, text/xml, and text/plain. These resources are commonly used for XHR requests to provide data that web applications can use to create rich experiences. Compressing them will likely improve user experience. Vector graphics such as image/svg+xml, and image/x-icon are not often thought of as text based, but they are and sites that use them would benefit from compression.
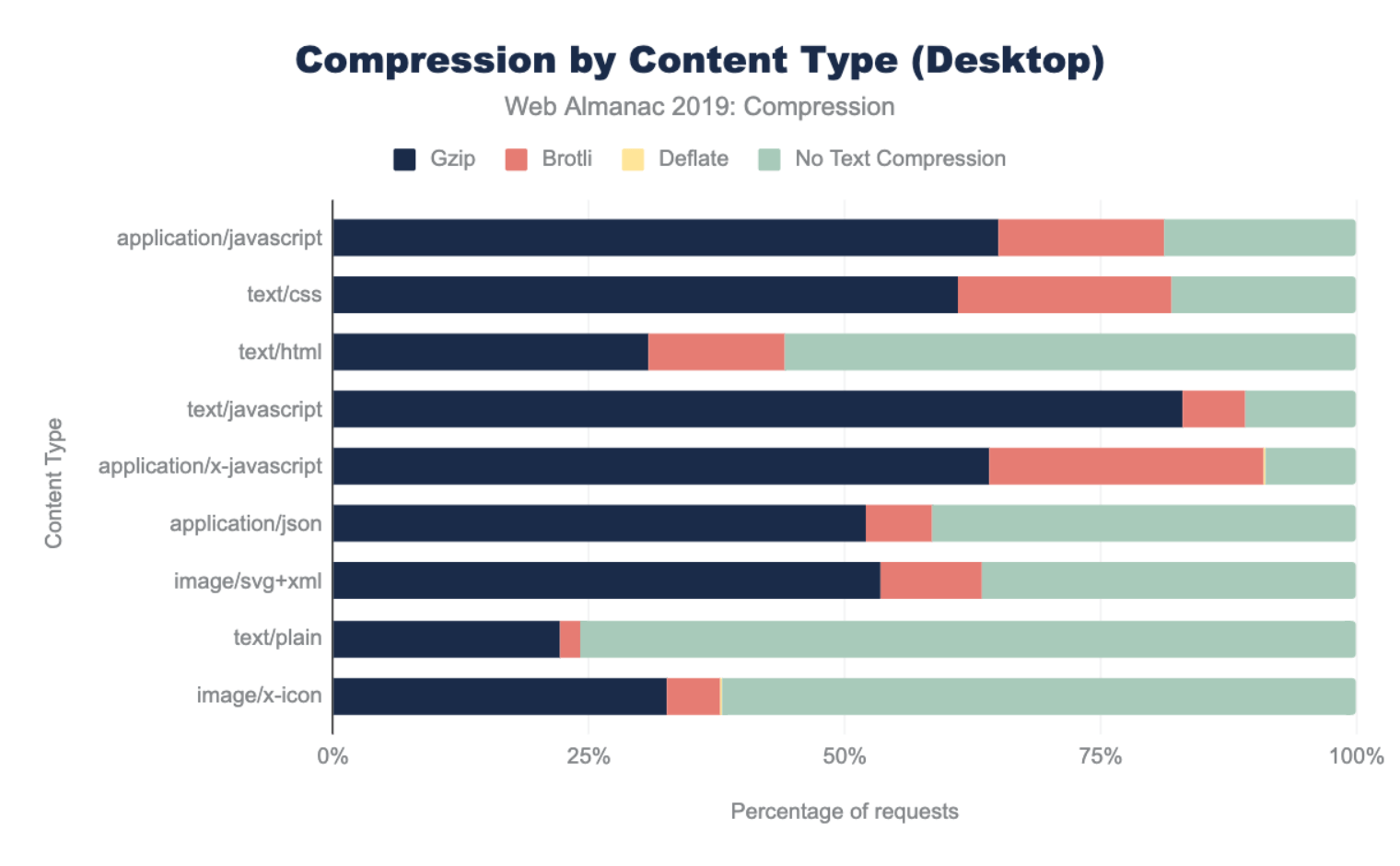
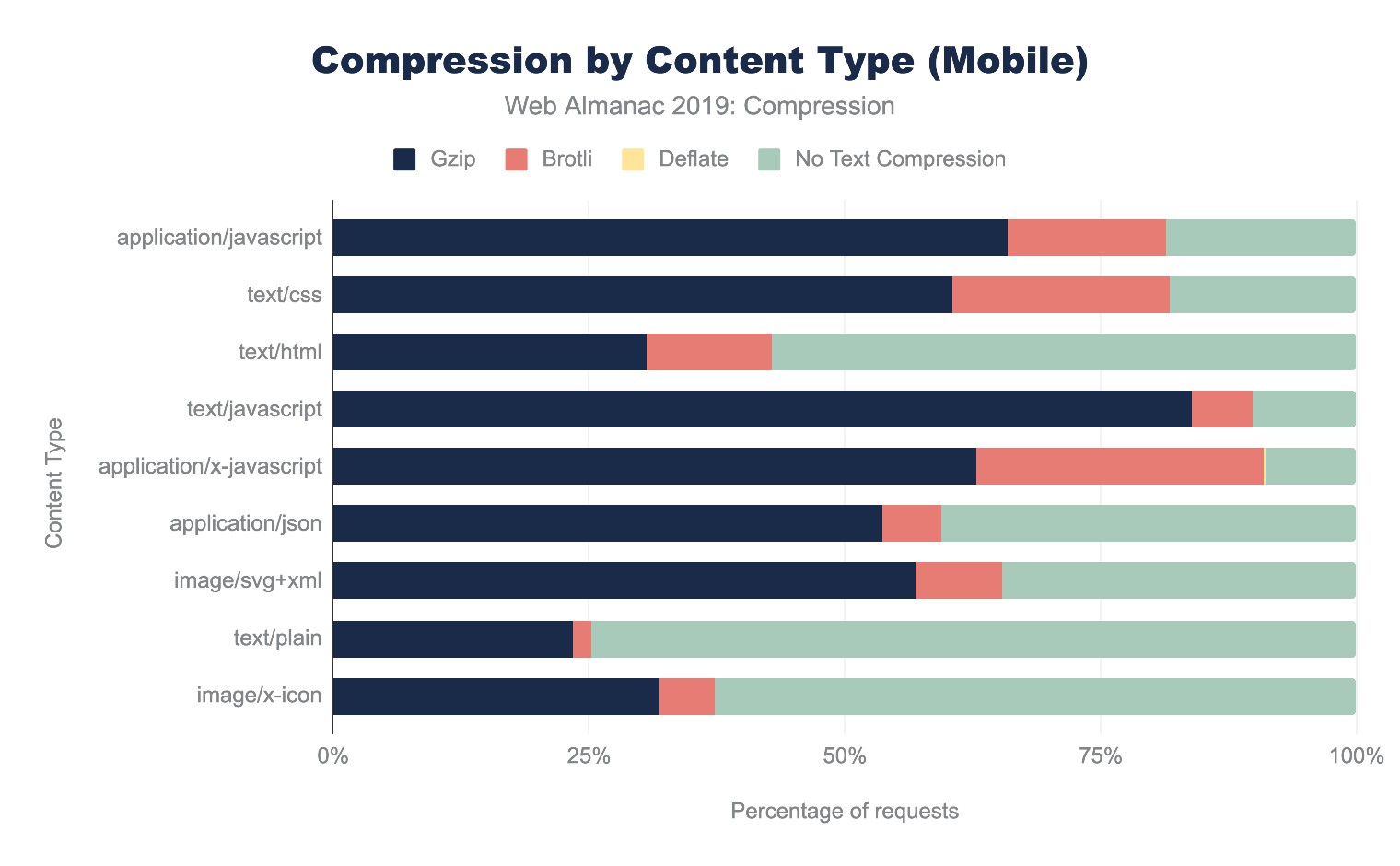
Across all content types, Gzip is the most popular compression algorithm. The newer Brotli compression is used less frequently, and the content types where it appears most are application/javascript, text/css and application/x-javascript. This is likely due to CDNs that automatically apply Brotli compression for traffic that passes through them.
First-party vs third-party compression
In the Third Parties chapter, we learned about third parties and their impact on performance. When we compare compression techniques between first and third parties, we can see that third-party content tends to be compressed more than first-party content.
Additionally, the percentage of Brotli compression is higher for third-party content. This is likely due to the number of resources served from the larger third parties that typically support Brotli, such as Google and Facebook.
| Desktop | Mobile | |||
|---|---|---|---|---|
| Content Encoding | First-Party | Third-Party | First-Party | Third-Party |
| No Text Compression | 66.23% | 59.28% | 64.54% | 58.26% |
gzip |
29.33% | 30.20% | 30.87% | 31.22% |
br |
4.41% | 10.49% | 4.56% | 10.49% |
deflate |
0.02% | 0.01% | 0.02% | 0.01% |
| Other / Invalid | 0.01% | 0.02% | 0.01% | 0.02% |
Identifying compression opportunities
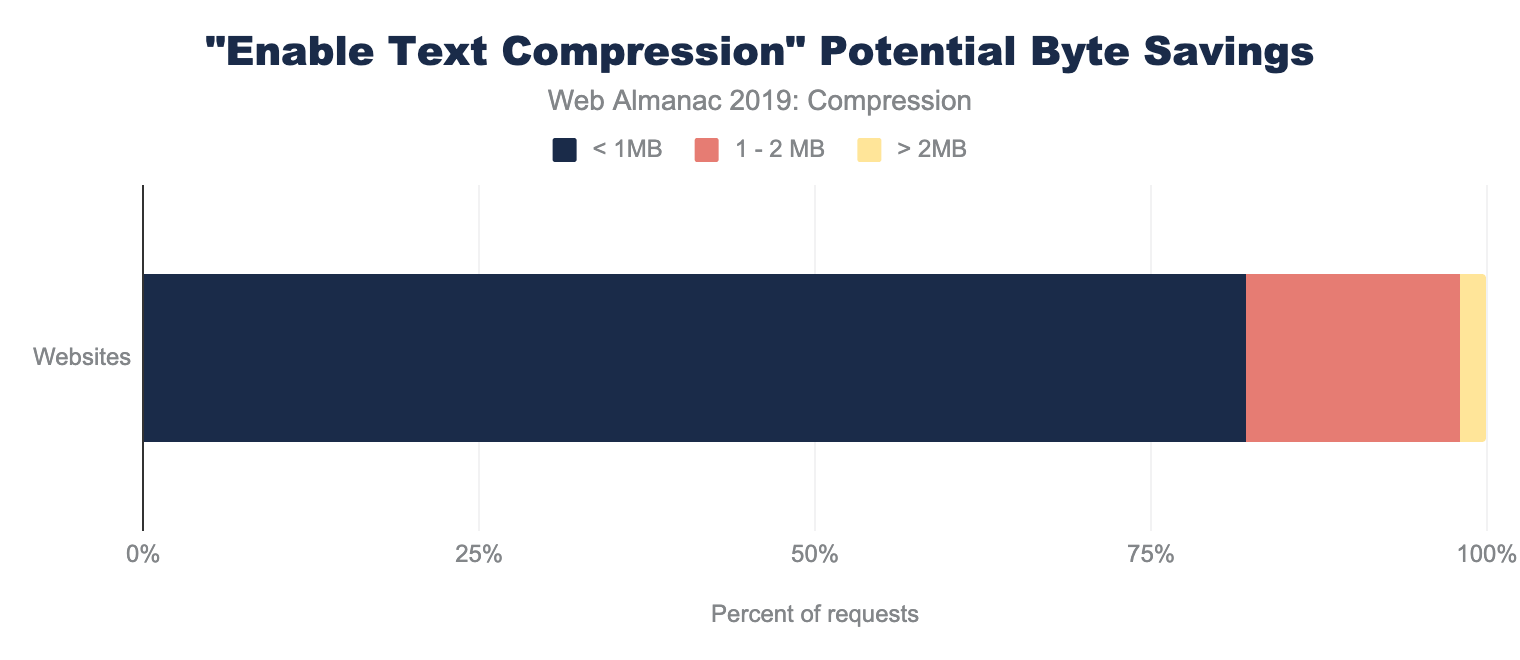
Google’s Lighthouse tool enables users to run a series of audits against web pages. The text compression audit evaluates whether a site can benefit from additional text-based compression. It does this by attempting to compress resources and evaluate whether an object’s size can be reduced by at least 10% and 1,400 bytes. Depending on the score, you may see a compression recommendation in the results, with a list of specific resources that could be compressed.
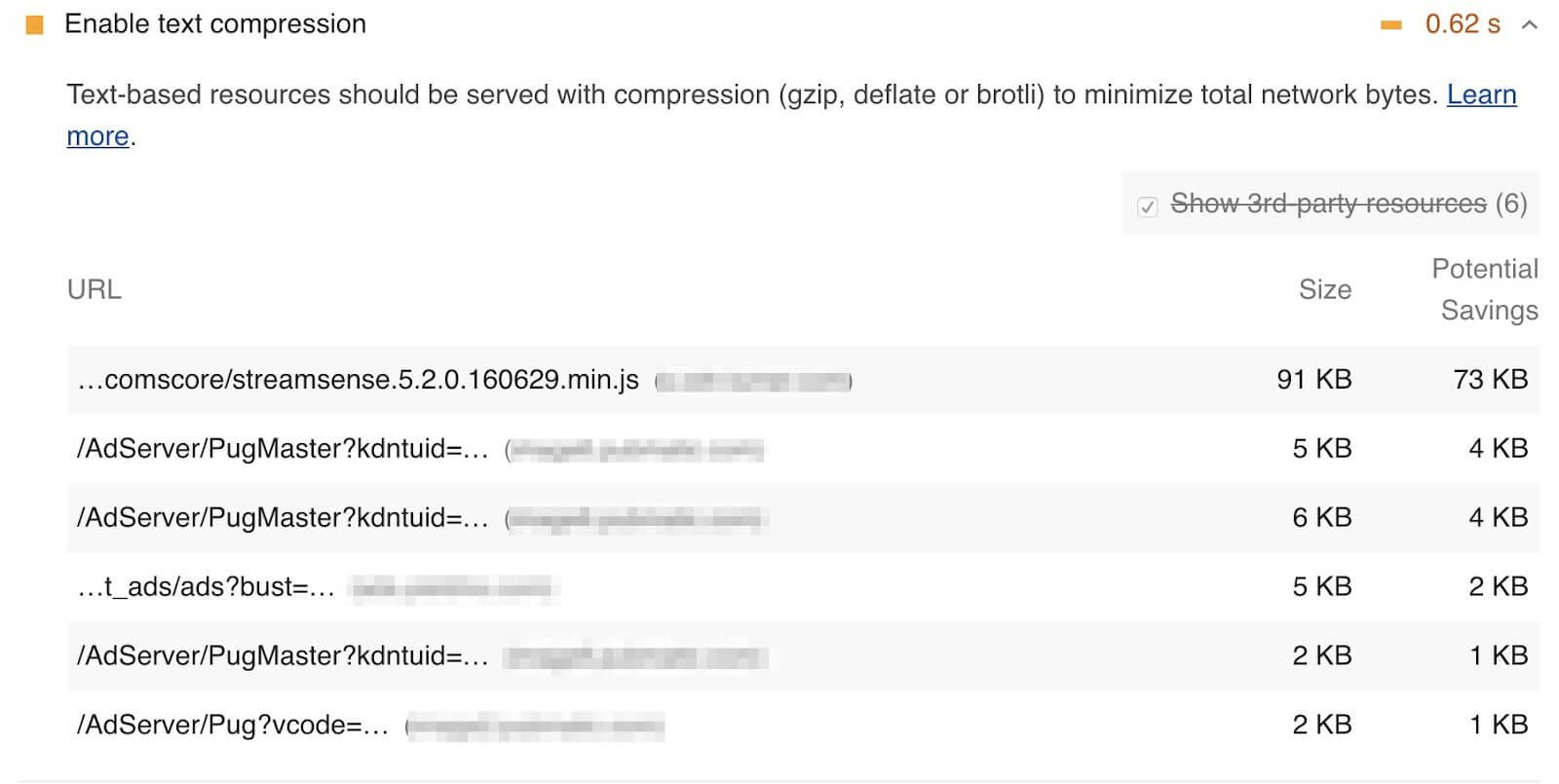
Because the HTTP Archive runs Lighthouse audits for each mobile page, we can aggregate the scores across all sites to learn how much opportunity there is to compress more content. Overall, 62% of websites are passing this audit and almost 23% of websites have scored below a 40. This means that over 1.2 million websites could benefit from enabling additional text based compression.
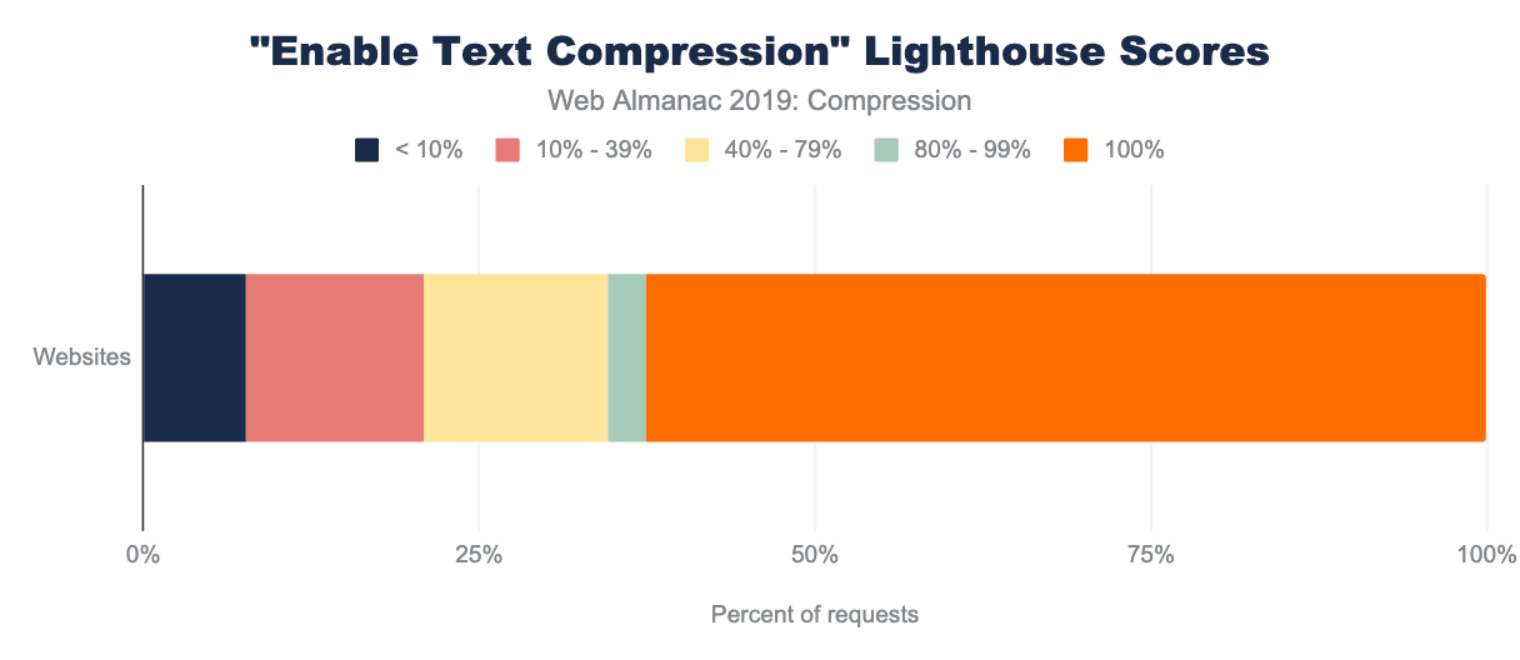
Lighthouse also indicates how many bytes could be saved by enabling text-based compression. Of the sites that could benefit from text compression, 82% of them can reduce their page weight by up to 1 MB!
Conclusion
HTTP compression is a widely used and highly valuable feature for reducing the size of web content. Both Gzip and Brotli compression are the dominant algorithms used, and the amount of compressed content varies by content type. Tools like Lighthouse can help uncover opportunities to compress content.
While many sites are making good use of HTTP compression, there is still room for improvement, particularly for the text/html format that the web is built upon! Similarly, lesser-understood text formats like font/ttf, application/json, text/xml, text/plain, image/svg+xml, and image/x-icon may take extra configuration that many websites miss.
At a minimum, websites should use Gzip compression for all text-based resources, since it is widely supported, easily implemented, and has a low processing overhead. Additional savings can be found with Brotli compression, although compression levels should be chosen carefully based on whether a resource can be precompressed.
