Privacy

Introduction
Users face significant privacy issues when they browse the web. For example, most websites visited by the user contain trackers, which observe user activities and profile them. Profiled user activities are then used for various privacy-invasive purposes, such as targeted personalized online advertising and direct selling of user data.
Trackers deploy a wide range of techniques to track users on the web, such as cookies (both first and third-party), browser fingerprinting, and use of personally identifiable information (such as email addresses).
To protect their privacy, users rely on privacy-enhancing tools—such as ad and tracker blockers—which stop online trackers from loading on web pages. Similarly, browsers are deploying privacy-protections in the browser that aim to eliminate several privacy issues by design, such as blocking of third-party cookies.
Unfortunately, trackers engage in an arms-race with privacy-enhancing technologies and continuously explore mechanisms to bypass privacy protections in the browser—recently with bounce tracking and CNAME tracking. Over the last few years, governments have stepped in with data protection regulations—such as CCPA in California and GDPR in EU—which provide mechanisms for users to exercise their rights, such as not consenting to data collection.
In this chapter, we provide an overview of online tracking (including the mechanism used for online tracking, such as cookies and browser fingerprinting), privacy protections provided by the browsers to eliminate some privacy issues by design (for example, User-Agent Client Hints), techniques used by online trackers to bypass privacy-protections (for example, bounce tracking), and adoption of protections offered to users under data protection regulations (for example, CCPA adoption by websites).
Online tracking
We mostly leverage data from WhoTracks.Me, a publicly available list that catalogs third-party trackers present across a wide range of websites. By utilizing this resource, we identify the most prevalent trackers on the websites. This helped us assess the dominance of certain tracking companies and better understand the overall landscape of third-party tracking. It’s important to note that WhoTracks.Me identifies several trackers at the domain level. While a significant number of URLs associated with these domains engage in tracking, not all URLs from those domains necessarily do.
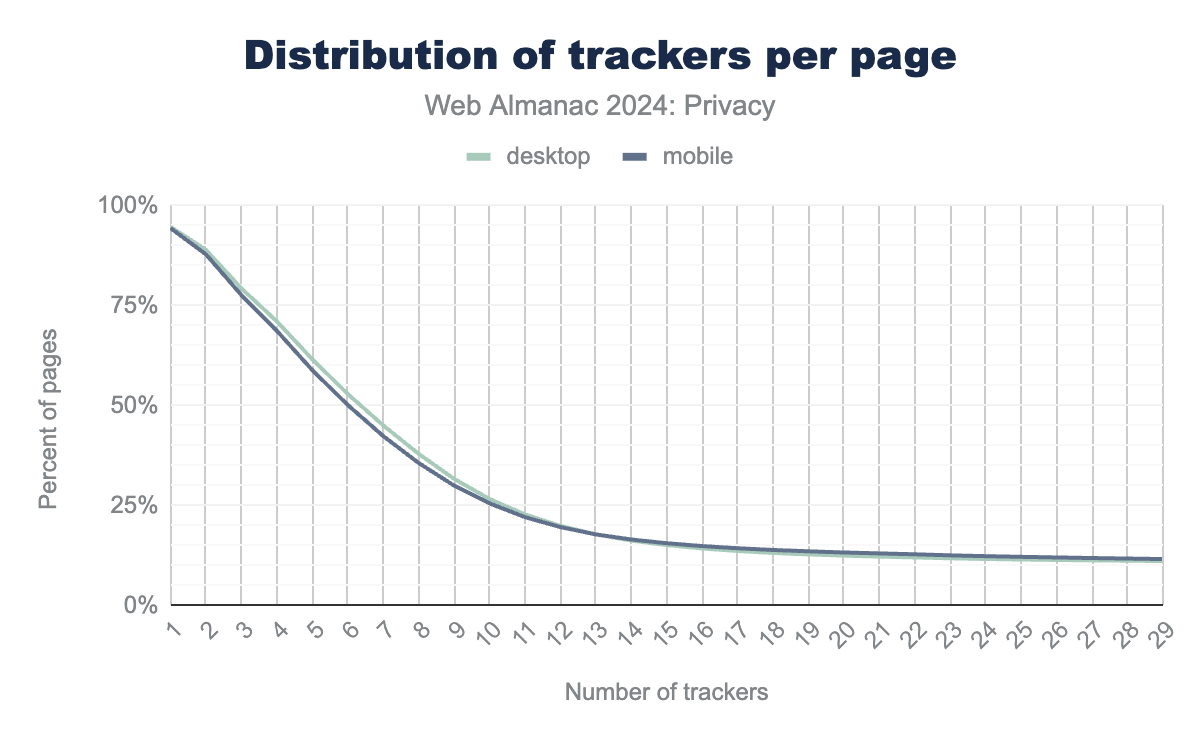
Online tracking is a routine practice on the internet. A significant number of websites include specialized online services that record user activities within their website and across sites. Our findings reveal that 95% of the desktop and 94% of the mobile websites include at least one tracker.
We also note that more than a quarter of both desktop (27%) and mobile (26%) sites contain more than 10 trackers. These trackers enable companies to build detailed user profiles based on online behavior, which are regularly used for personalized advertising and to provide insights to website owners. In the following sections, we explore the various techniques trackers use to monitor user activity and examine how they attempt to bypass the privacy protections introduced by modern browsers.
Stateful tracking
Online tracking is broadly classified into two categories: stateful and stateless tracking. Stateful tracking involves storing information about a user directly on their device, typically through cookies and also through other storage mechanisms such as the local storage, that persists across sessions.
When users visit the websites where such trackers are embedded, the cookies associated with these trackers are automatically included in the network requests. Thus tracking services that are embedded on several websites are able to observe all the websites which the user has visited.
Third-party tracking services
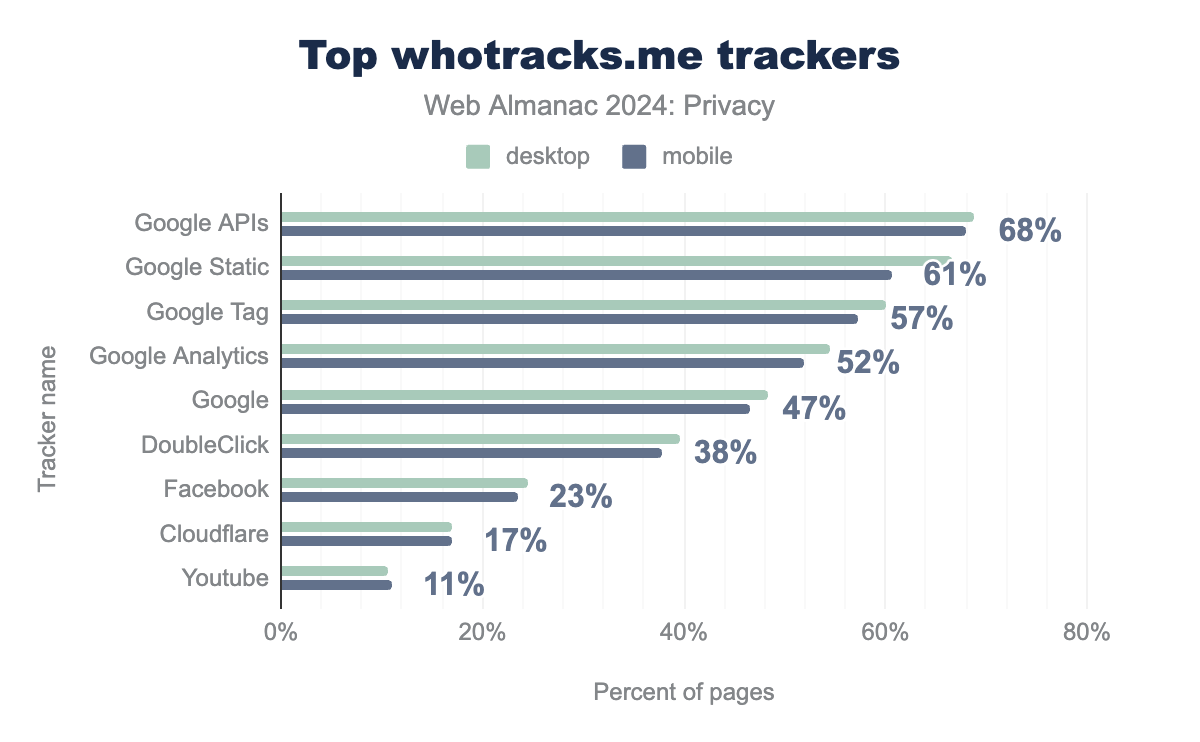
The following figure provides the distribution of prevalence of online tracking domains.
We note that Google-owned domains dominate the tracking landscape, with googleapis.com and Google’s gstatic.com appearing on the highest percentage of pages—68% and 61%, respectively. Other prominent trackers include Google Tag and Google Analytics, each seen on over 50% of pages, highlighting the significant reach of Google’s tracking services. In addition to Google and its associated services, we also observe a notable presence of Facebook and Cloudflare.
Third-party cookies
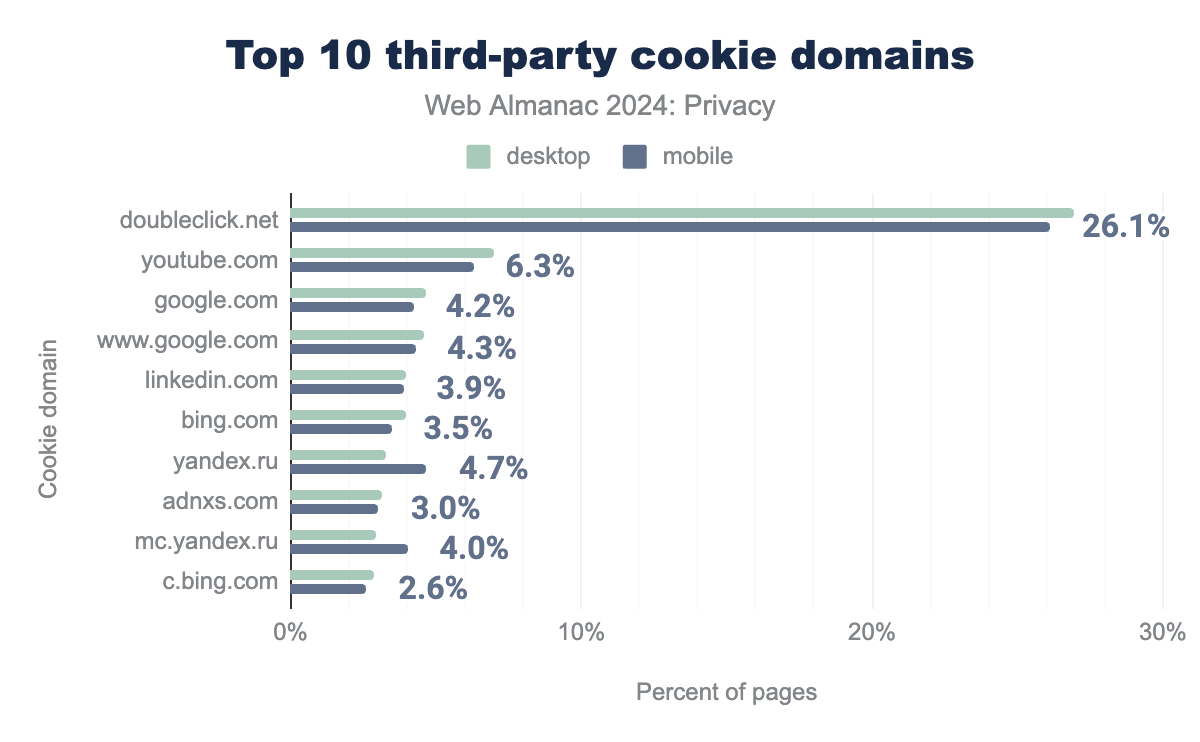
doubleclick.net (27% desktop; 26% mobile), youtube.com (7% desktop; 6% mobile), google.com (5% desktop; 4% mobile), www.google.com (5% desktop; 4% mobile), linkedin.com (4% desktop; 4% mobile), bing.com (4% desktop; 3% mobile), yandex.ru (3% desktop; 5% mobile), adnxs.com (3% desktop; 3% mobile), mc.yandex.ru (3% desktop; 4% mobile), c.bing.com (3% desktop; 3% mobile), yandex.com (3% desktop; 4% mobile), mc.yandex.com (3% desktop; 4% mobile), adsrvr.org (3% desktop; 3% mobile), googleadservices.com (3% desktop; 3% mobile), yahoo.com (3% desktop; 3% mobile).Third-party cookies are the main mechanism used to track users on the web. Our measurements reveal that Google’s doubleclick.com is the largest source of third-party cookies, with presence on more than a quarter of the crawled web pages. Compared to the 2022 analysis, the top sources of third-party cookies have remained largely static, with the notable absence of Facebook, previously the second-largest source of third-party cookies. However, as shown in the next section, we instead see a significant number of cookies set by Facebook in the first-party context.
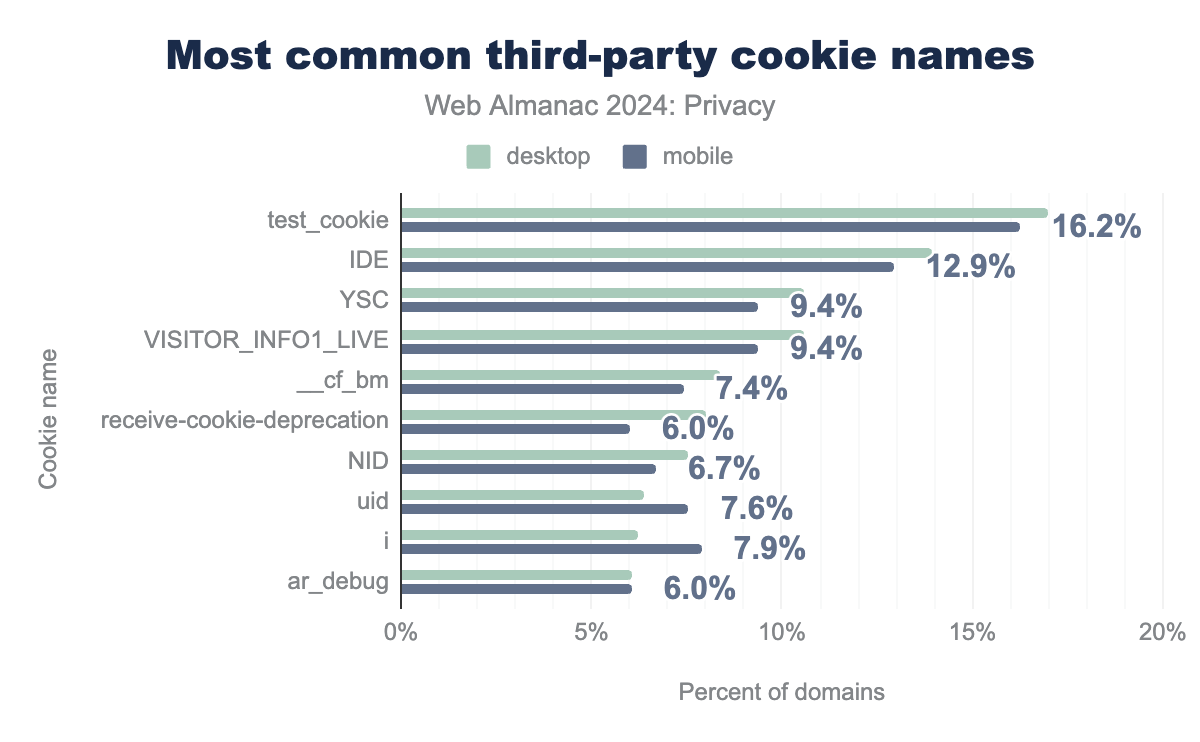
test_cookie (17% desktop; 16% mobile), IDE (14% desktop; 13% mobile), YSC (11% desktop; 9% mobile), VISITOR_INFO1_LIVE (11% desktop; 9% mobile), __cf_bm (8% desktop; 7% mobile), receive-cookie-deprecation (8% desktop; 6% mobile), NID (8% desktop; 7% mobile), uid (6% desktop; 8% mobile), i (6% desktop; 8% mobile), ar_debug (6% desktop; 6% mobile), c (5% desktop; 7% mobile), _GRECAPTCHA (5% desktop; 5% mobile), bcookie (4% desktop; 5% mobile), lidc (4% desktop; 5% mobile), MUID (4% desktop; 4% mobile).In order to identify trackers that share cookies across many domains, we also examine the most common names for third-party cookies. We note that the top four cookie names correspond to cookies set by Google’s advertising products and Youtube, as described in their documentation, and the fifth most-common name corresponds to a cookie set by Cloudflare. Cloudflare’s cookie, __cf_bm, is used to “identify and mitigate automated traffic”. As this cookie is set on the domains of Cloudflare’s individual customers, it is not captured in a per-domain ranking of cookies.
First-party cookies
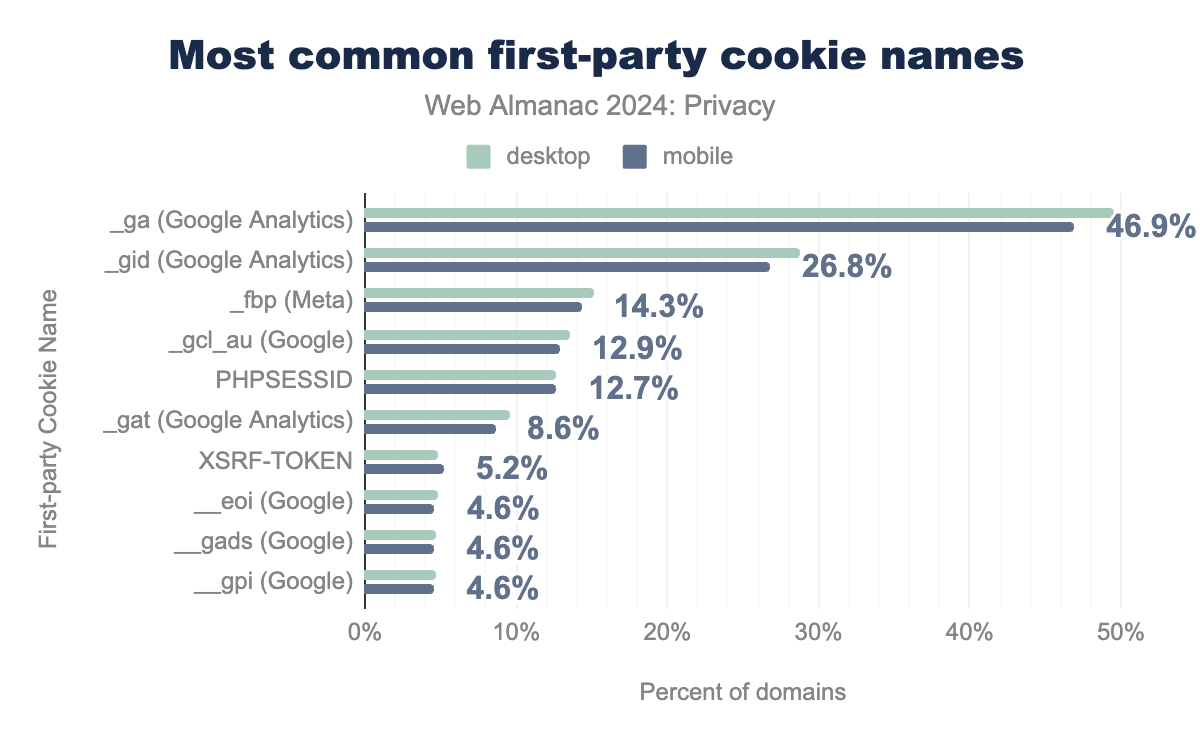
_ga (49% desktop; 47% mobile), _gid (29% desktop; 27% mobile), _fbp (15% desktop; 14% mobile), _gcl_au (14% desktop; 13% mobile), PHPSESSID (13% desktop; 13% mobile), _gat (10% desktop; 9% mobile), XSRF-TOKEN (5% desktop; 5% mobile), __eoi (5% desktop; 5% mobile), __gads (5% desktop; 5% mobile), __gpi (5% desktop; 5% mobile), sbjs_current (4% desktop; 4% mobile), sbjs_session (4% desktop; 4% mobile), sbjs_udata (4% desktop; 4% mobile), sbjs_first (4% desktop; 4% mobile), sbjs_first_add (4% desktop; 4% mobile)When measuring common first-party cookies, we see extensive evidence of analytics and advertising services setting cookies in the first-party context. The top two cookies, _ga and _gid, are both part of Google Analytics.
The next cookie, _fbp, is a tracking cookie set by Meta. Since 2022, Meta’s cookie tracking appears to have moved primarily from the third-party context into the first-party context; the default setting for the Meta Pixel now sets first-party cookies .
The majority of the remaining cookies match cookies set by Google, as described in their documentation. First-party cookies can be used either to track activity on a single site or for cross-site tracking; we do not attempt to determine the exact purpose of these cookies. Only two of the top cookie names, PHPSESSID and XSRF-TOKEN, have a clear non-tracking purpose. PHPSESSID is the default cookie name used by the PHP framework to store the user’s session ID, and XSRF-TOKEN is a default name used by the Angular framework.
The Cookies chapter further describes the details and usage trends of cookies.
Stateless tracking
In contrast to stateful tracking, where identifiers are stored in the browser, in stateless tracking, identifiers are generated at runtime. These identifiers often depend on unique characteristics of the user’s device or browser. Although this method may be less reliable than stateful tracking, it is typically more difficult to identify and block.
Browser fingerprinting
Browser fingerprinting is one of the most common stateless tracking techniques. To conduct browser fingerprinting, trackers use device configuration information exposed by the browser through JavaScript APIs (for example, Canvas) and HTTP headers (for example, User-Agent).
As browsers continue to expand the restrictions placed on cookies, fingerprinting has become an attractive alternative. Prior studies have found that fingerprinting is now common and is increasing in prevalence. Here, we attempt to determine the most common sources of fingerprinting across the web.
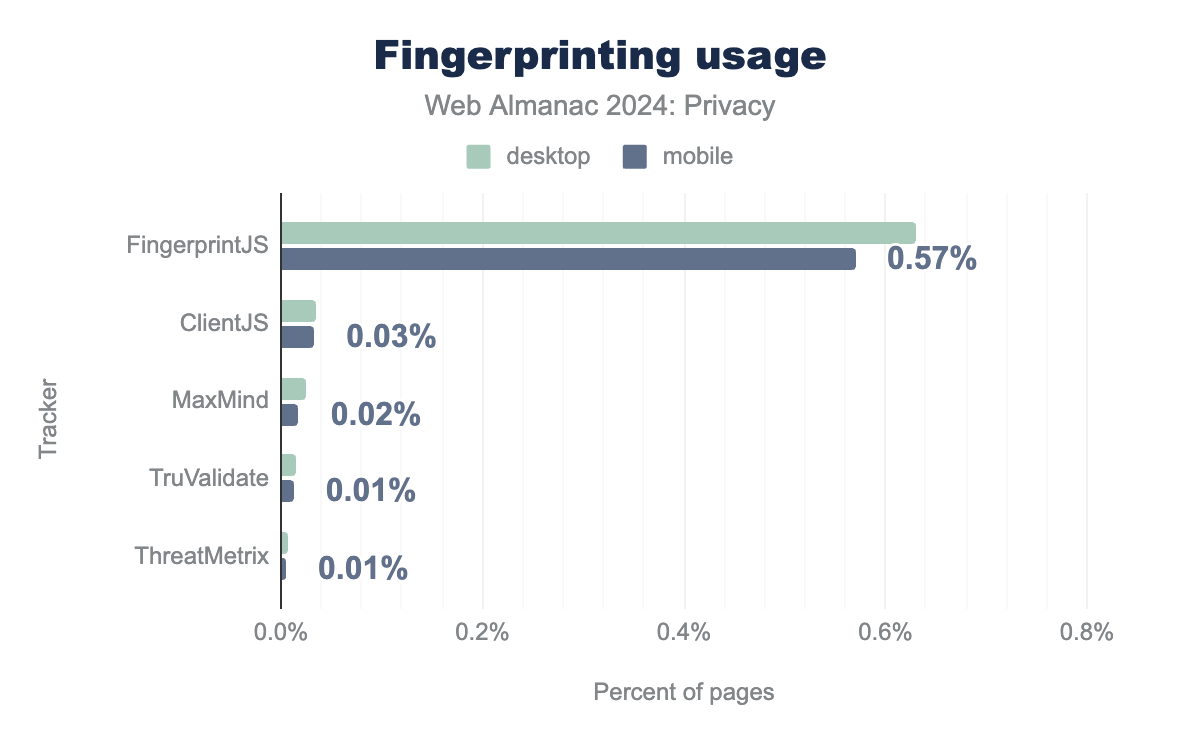
In our analysis, we first looked for the presence of well-known fingerprinting libraries. We found that, among the libraries tested, the most prevalent library used on the web to perform fingerprinting is FingerprintJS (FingerprintJS), which we found on 0.57% of all websites. Most likely this is because the library is open source, and has a free version. Compared to our measurements from 2022, we find that the use of these fingerprinting libraries has slightly decreased; however, it is important to note that this year we crawl roughly ~4 million extra web pages.
While we detect the prevalence of well-known fingerprinting vendors, there are several other services (including first-part scripts) that may engage in fingerprinting. To identify such potential sources of fingerprinting, we start by examining the source code of the commonly-used fingerprinting library FingerprintJS. We then compile a list of APIs used by the library, and search for the occurrences of these APIs in all of the crawled scripts. We mark any script with 5 or more usages as a potential fingerprinting script. We then rank the scripts by the number of pages on which they are loaded.
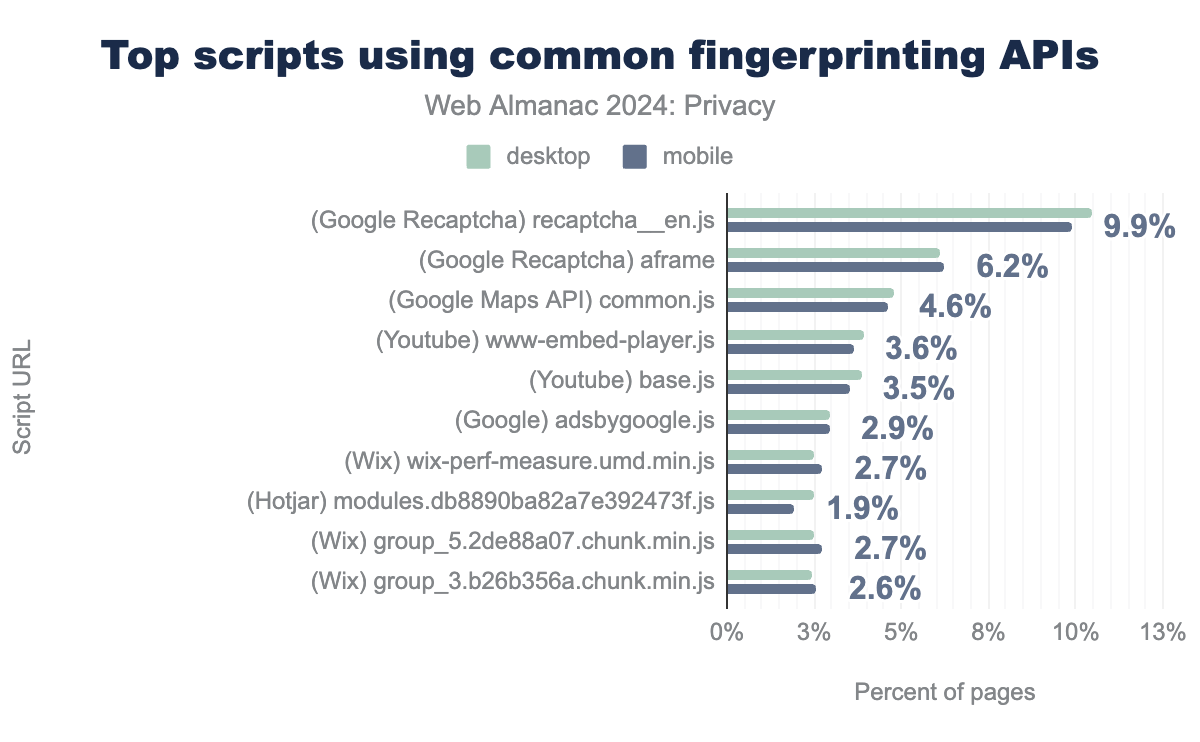
recaptcha__en.js (Google Recaptcha) (10% desktop; 10% mobile), aframe (Google Recaptcha) (6% desktop; 6% mobile), common.js (Google Maps API) (5% desktop; 5% mobile), www-embed-player.js (Youtube) (4% desktop; 4% mobile), base.js (Youtube) (4% desktop; 4% mobile), adsbygoogle.js (Google) (3% desktop; 3% mobile), wix-perf-measure.umd.min.js (Wix) (3% desktop; 3% mobile), modules.db8890ba82a7e392473f.js (Hotjar) (2% desktop; 2% mobile), group_5.2de88a07.chunk.min.js (Wix) (2% desktop; 3% mobile), group_3.b26b356a.chunk.min.js (Wix) (2% desktop; 3% mobile), tpaCommons.1b788520.chunk.min.js (Wix) (2% desktop; 3% mobile), Qj-BdKDLI_z.js (Facebook) (2% desktop; 2% mobile), tag.js (Yandex Metrika) (2% desktop; 3% mobile), main.cd290f82.bundle.min.js (Wix) (2% desktop; 3% mobile), thunderbolt-commons.35876736.bundle.min.js (Wix) (2% desktop; 2% mobile)We find a mixture of scripts that are primarily used for tracking, and scripts that also have a non-tracking purpose. Recaptcha, the most common script, is known to use fingerprinting to separate humans from bots. Google Ads and Yandex Metrika are also primarily tracking scripts. However, other scripts, such as the Google Maps API and Youtube embed API, also have a non-tracking purpose, and so their usage of these APIs may have purposes other than fingerprinting. Further manual analysis is required to confirm whether these scripts are actually performing fingerprinting.
Evading tracking protections
As tracking protections such as third-party blocking by cookies are becoming common on web browsers trackers are increasingly exploring mechanisms to bypass them. These methods exploit browser functionality and DNS configurations, enabling persistent tracking even as privacy measures become more stringent.
We examined two prominent tracking protection evasion practices: CNAME tracking and bounce tracking, and looked into how prevalent these are on the web and how browsers are trying to reduce these and maintain user privacy by default.
CNAME cloaking
CNAME cloaking leverages the DNS CNAME record to mask third-party trackers as first-party entities. A CNAME record allows a subdomain to point to another domain. Trackers utilize this by setting up a CNAME record on a subdomain of the website they are embedded within. For example, tracker.example.com could point to tracker.trackingcompany.com. When the tracker sets a cookie, it appears to originate from example.com, effectively becoming a first-party cookie and bypassing many third-party cookie blocking mechanisms. This tactic is particularly effective because most tracking protection measures concentrate on restricting third-party access, while first-party cookies are generally allowed for essential website functionality.
Our analysis of DNS data identifies CNAME records used by requests originating from the website’s primary domain and pointing to third-party domains. While CNAME records can legitimately be used by hosting services like CDNs, they can also be exploited for tracking. To focus on tracking-specific usage, we cross-referenced identified domains with AdGuard tracker list and used data from WhoTracks.Me to filter out primarily hosting-related domains.
In 2022, our analysis of CNAME cloaking relied on mapping first-party hostnames with the AdGuard’s disguised CNAME hostnames list. This year’s analysis incorporates a significant enhancement: the collection of actual DNS records for each requested hostname originating from a given page. This direct DNS resolution allows for precise identification of hostnames with CNAME records that redirect to third-party domains, providing a more accurate and comprehensive view of CNAME cloaking activity. This improved methodology has enabled us to identify previously undocumented trackers associated with utiq.com, truedata.co, actioniq.com and others, and contribute these back to the AdGuard list.
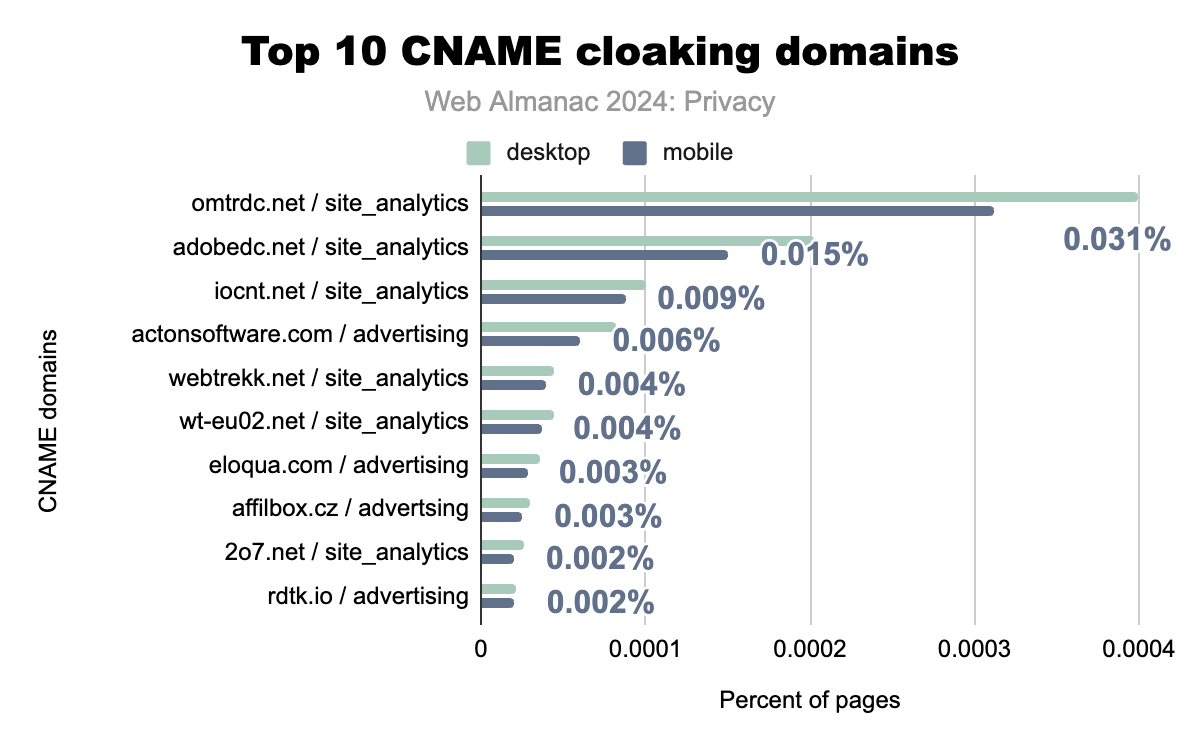
omtrdc.net and adobedc.net related to Adobe Analytics being the two most prevalent cloaking domains on both platforms. omtrdc.net used appears on 0.031% of mobile pages and 0.04% on desktop. adobedc.net ranks second with 0.015% prevalence on mobile. The remaining domains each account for 0.01% or less of pages. Generally, these CNAME cloaking domains are more common on desktop than mobile web pages.The 2024 Web Almanac data reveals a continuing trend of CNAME cloaking, with omtrdc.net and adobedc.net, both associated with Adobe Analytics, leading the site analytics category with appearances on over 0.031% (~9,000) and 0.015% (~4,500) mobile pages respectively.
The prevalence of analytics-related domains suggests that CNAME cloaking is not solely confined to advertising, but is also utilized for broader data collection purposes. The presence of actionsoftware.com and other advertising-related domains further solidifies the use of this technique for targeted advertising.
The data highlights that while overall CNAME usage remains relatively low compared to traditional tracking methods, its concentration on high-traffic websites presents a significant privacy concern for a large number of users.
Bounce tracking
Bounce tracking represents another sophisticated evasion technique that allows trackers to read cookies from their first-party context. More specifically, bounce tracking tricks the browser into visiting the tracking domain as a first-party site, allowing it to read and write cookies from its first-party storage. Instead of directly communicating with a tracking server, the browser is first redirected to an intermediary domain—the “bounce” domain (demo). Thus in case third-party cookies are blocked, trackers can read persistent identifiers from their first-party storage. This intermediary then redirects to the actual website.
This navigation pattern is similar to functional patterns, such as federated authentication (for example, OAuth), which makes it challenging to block bounce tracking. However, web browsers, such as Chrome (when opted-in to blocking third-party cookies), Safari, Brave and Firefox have deployed or are in the process of deploying mitigation against bounce tracking.
Given the constrained nature of the crawl, limited to the loading of a specific set of pages, our analysis of redirections encompassed only those returning to the originating page after navigating to another page. We identify bounce tracking by detecting instantaneous redirects to a third-party tracker that sets a first-party cookie before returning the user to the original page.
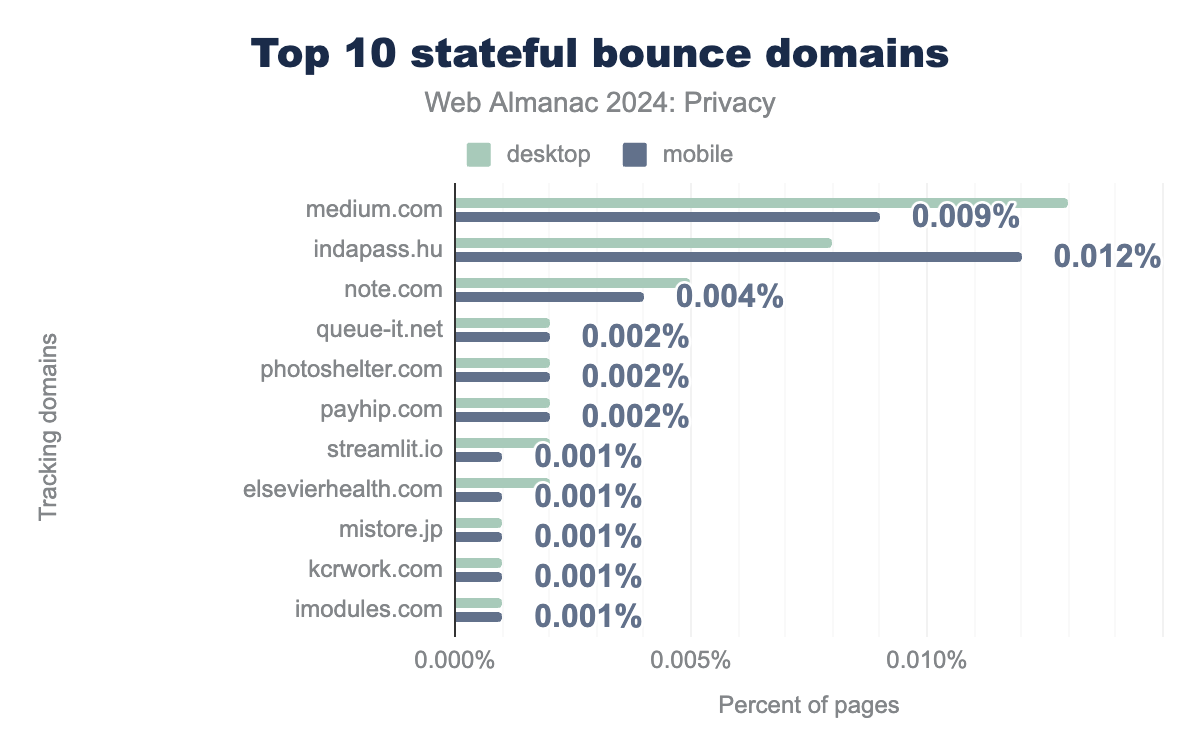
indapass.hu being most common on mobile and medium.com being more common on desktop. medium.com leads with 0.009% of mobile and 0.013% on desktop pages. indapass.hu follows at 0.012% primarily on mobile. note.com accounts for around 0.004% of pages. The remaining domains—queue-it.net, photoshelter.com, payhip.com, streamlit.io, elsevierhealth.com, mistore.jp, kcrwork.com, and imodules.com—each represent roughly 0.002% or less.
We note that medium.com (available on 0.009% or 1,515 mobile and 0.013% or 1,641 desktop pages) and indapass.hu (IndaMedia) (0.012% or 1,991 mobile pages) appear the most in bounce tracking like navigations. These companies use bounce tracking to manage a global identity of the visitors to count visits and improve services (both Medium and IndaMedia are publishing companies)
Our analysis, limited to crawlable pages, is not exhaustive, and not all identified domains necessarily exhibit privacy-intrusive behavior. Legitimate uses, like SSO (for example login.taobao.com) and payment solutions can often be distinguished from tracking by the presence of user interaction on the bounce domain.
Browser policies to improve privacy
It is a common practice for websites to include content from third-party services, such as the advertising and social media platforms. Unfortunately, third-party services cannot be implicitly trusted as, more often than not, they directly harm user privacy. For example by including third-party tracking services. See the Third Parties chapter for a more detailed analysis.
Recently, web standards bodies and browser vendors have tried to step in and provide many controls to website developers that they can use to mitigate privacy threats posed by third-party services. We analyze the prevalence of such prominent browser-provided controls. Note that some of the browser policies, such as Permissions Policy, have both security and privacy implications; we discuss such policies in the Security chapter.
User-Agent Client Hints
In an effort to minimize the amount of information exposed about the browsing environment, particularly through the User-Agent string, the User-Agent Client Hints mechanism is introduced by browsers and standards bodies.
The key idea is that the websites that want to access certain high entropy information about the users’ browsing environment have to set a header (Accept-CH) in the first response.
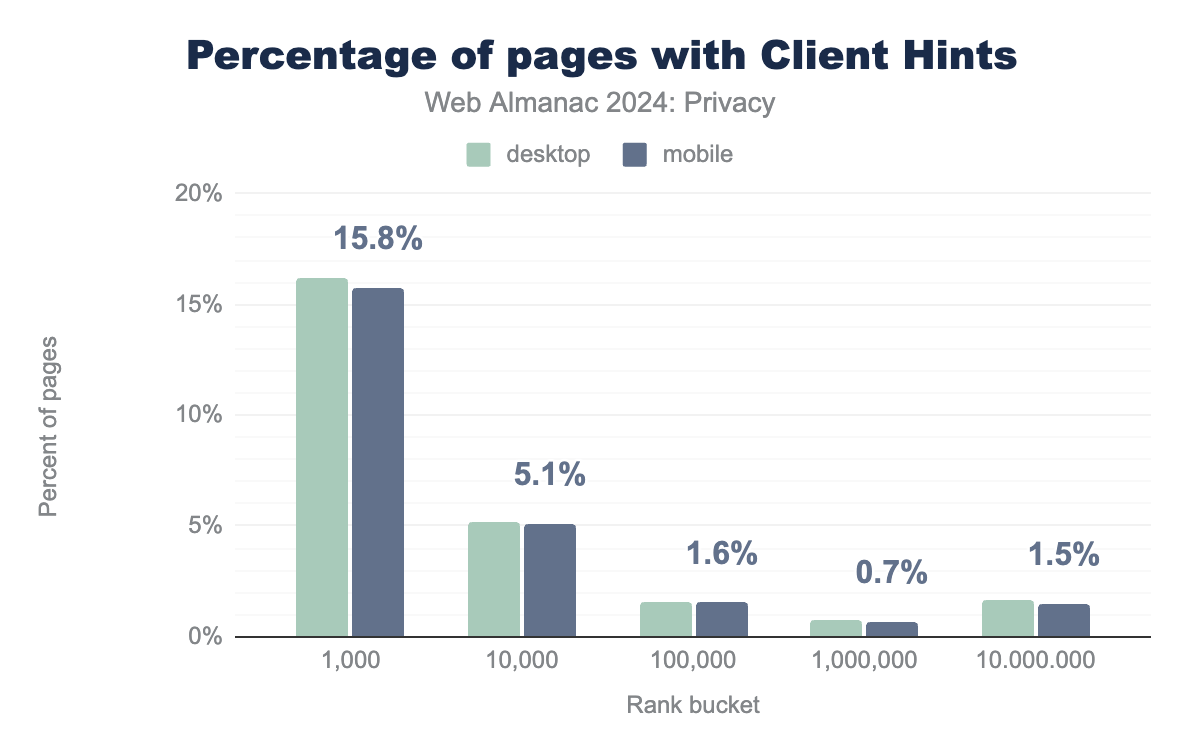
We note that it is deployed by 15.8% of the top 1,000 and 5.1% of the top 10,000 mobile websites. When we look at the adoption of sites that respond with the Accept-CH header in comparison with the results from 2022 chapter (top 1,000: 9.11%, top 10,000: 3.12%), we see an increase in adoption by 6.69% for the 1,000 popular sites. We surmise that this increase in adoption is related to the fact that Chromium has been reducing the information that is shared in the User-Agent string (through the User-Agent Reduction plan). For all websites, Accept-CH is deployed in 0.4% and 0.5% of all the crawled websites for desktop and mobile, respectively.
Referrer Policy
By default, most user agents include a Referer header, which discloses to third parties the website—or even the specific page—from which a request originated. This occurs for any resource embedded within a web page, as well as for requests triggered by a user clicking on a link. Consequently, third parties may gain insight into which website or page a particular user was visiting, leading to potential privacy concerns.
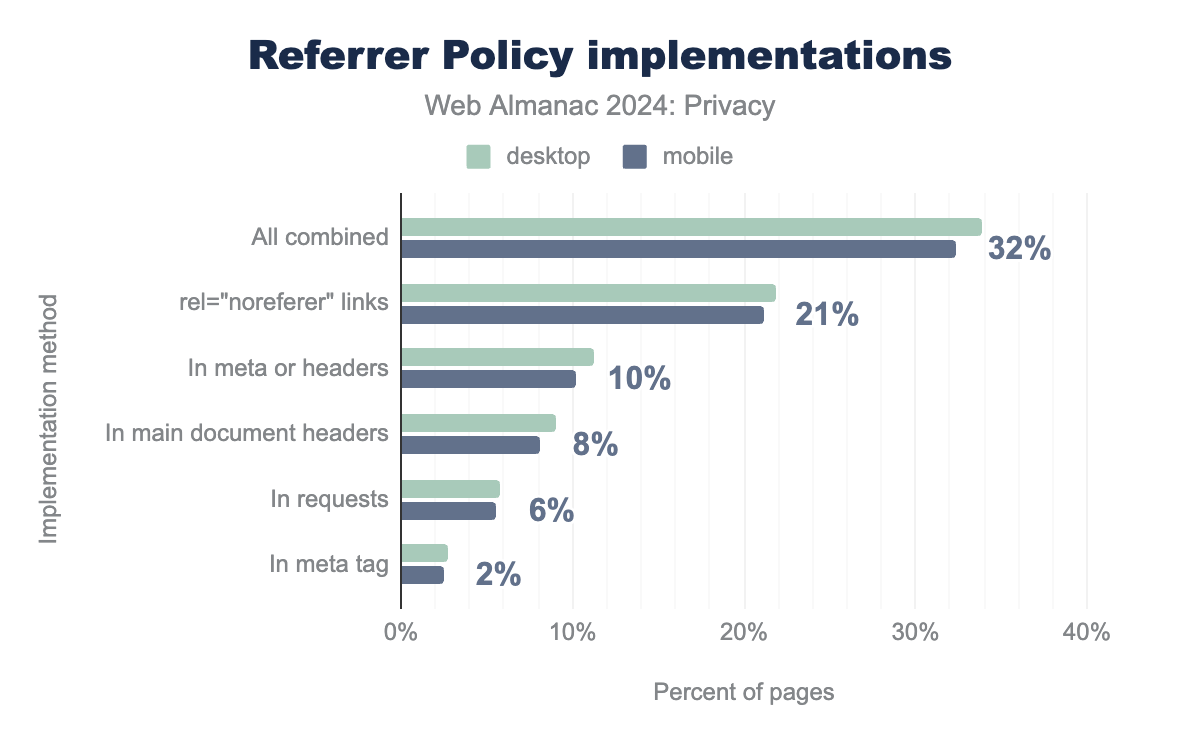
By making use of the Referrer Policy, websites can limit the instances in which the Referrer header is included in requests and thus improve user privacy.
Referrer policy can be included both at the document-level and also at the request-level. We find that referrer policy is deployed on 33.87% of the desktop web pages and 32% of the mobile web pages, overall. On 21.82% of such pages, Referrer Policy is deployed at the request-level with the ref=noreferer HTML tag, and in 11.31% of the instances, the referrer policy is deployed at the document level.
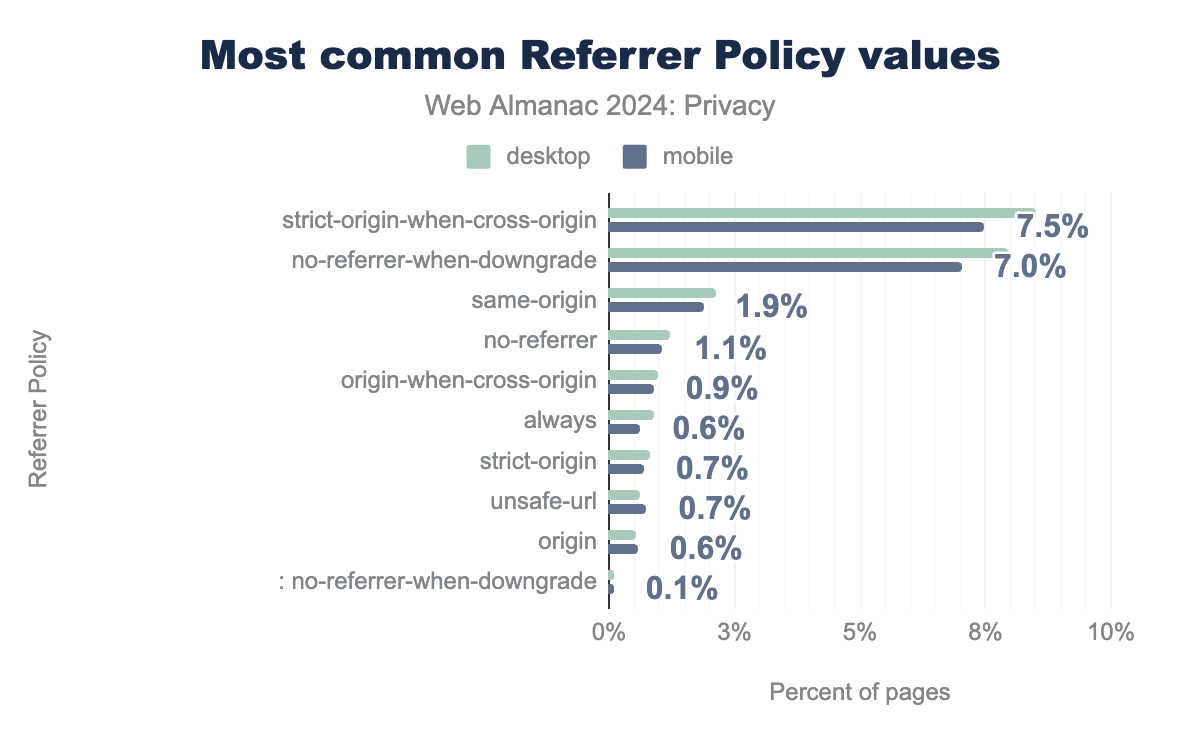
While referrer policy allows to mitigate some tracking, not all of its options have the same effect. Thus we next measure the deployment of individual referrer policy options.
Our analysis reveals that strict-origin-when-cross-origin is the most commonly used option of the Referrer Policy, with a deployment on 8% of the crawled web pages. We also note that its deployment has increased by nearly 3X as compared to 2022 chapter when it was deployed on only 2.68% of the crawled web pages.
strict-origin-when-cross-origin is also the default option if no policy is specified and only shares the full url in the referer header to the same-origin requests. For cross-origin requests, the path and the query string parameters are stripped out.
The next most commonly deployed option is no-referrer-when-downgrade, which does not include the Referer header on downgrade requests, that is, HTTP requests initiated on an HTTPS-enabled page. Unfortunately, this still leaks the page that the user is visiting in most scenarios—in HTTPS-enabled requests.
Privacy-related origins trials
Origin trials allow website developers to test new features released by web browsers (Chrome or FireFox) such as new browser APIs. Once website developers register in origin trials, the new browser features are made available to all their users. Since web browsers are increasingly deploying privacy-enhancing features, such as eliminating third-party cookies, we next analyze whether website developers are participating in privacy-related origin trials to assess their readiness for the upcoming privacy-enhancing features in browsers.
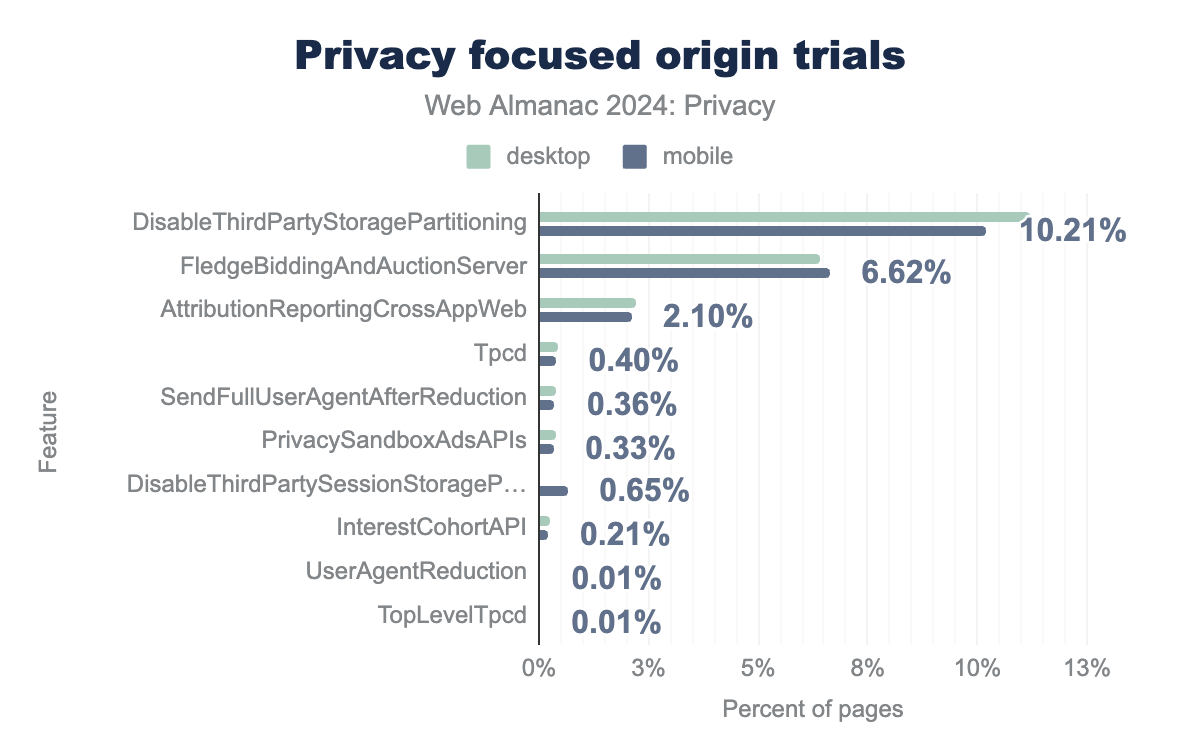
FledgeBiddingAndAuctionServer follows with 6.62% adoption on mobile. AttributionReportingCrossAppWeb sees 2.1% usage. The remaining features—Tpcd, SendFullUserAgentAfterReduction, PrivacySandboxAdsAPIs, DisableThirdPartySessionStoragePartitioning, InterestCohortAPI, UserAgentReduction, and TopLevelTpcd—all show significantly lower adoption rates, ranging from 0.65% down to 0.01%. In general, participation in most of these privacy-focused origin trials is relatively low, suggesting they are still in early stages of experimentation and adoption. The higher usage of DisableThirdPartyStoragePartitioning and FledgeBiddingAndAuctionServer indicates potentially greater interest or maturity in those particular privacy-preserving technologies.Among the privacy-enhancing features, we note that disableThirdPartyStoragePartitioning is the most widely used control with deployment on 10.21% of the mobile websites. disableThirdPartyStoragePartitioning allows a top-level site to un-partition (temporarily remove isolation by top-level site) in storage, service workers, and communication APIs in third-party content embedded on its pages.
It means that more than 10% of the websites are testing a feature that disables the benefits provided by the partitioning of third-party storage. Note that the storage partitioning applies to select storage related APIs that do not include cookies. The second most prevalent trial is FledgeBiddingAndAuctionServer with deployment over 6.62% of the mobile websites.
Privacy Sandbox proposals
Privacy Sandbox, introduced by Google in 2019, contains several proposals that are aimed at curbing privacy-invasive practices on the web by aiming to strike a balance between user privacy and the continued viability of online advertising, which supports free content and services on the web. Among privacy sandbox proposals, Topics, Protected Audience, and Attribution Reporting have garnered significant attention because of their implications on targeted advertising, interest-based ad auctions, and privacy-preserving conversion tracking, respectively. In this section, we measure the adoption of these proposals to assess the readiness of websites and ad-tech (for example, advertising platforms, tracking entities), in incorporating these proposals. Note that some of these proposals are not solely limited to Chrome, they are tested by other browsers such as Microsoft Edge.
We first provide the prevalence of these APIs. We note that Topics API, Protected Audience API (previously known as FLEDGE), and Attribution Reporting API have the highest presence across different advertising publishing technologies. These are respectively present on 33%, 63%, and 27% of top 1,000 websites. Amongst top 10 million websites, the presence drops to 7%, 63%, and 24%, respectively. Note that the presence does not imply the adoption of these APIs by websites.
Topics API
Google’s Topics proposal works by assigning a small set of high-level topics to a user based on their recent browsing activity, such as “sports” or “technology”. These topics are stored locally on the user’s devices and shared with websites and advertisers to serve relevant ads. Users also have the ability to see and control the topics that are shared with advertisers.
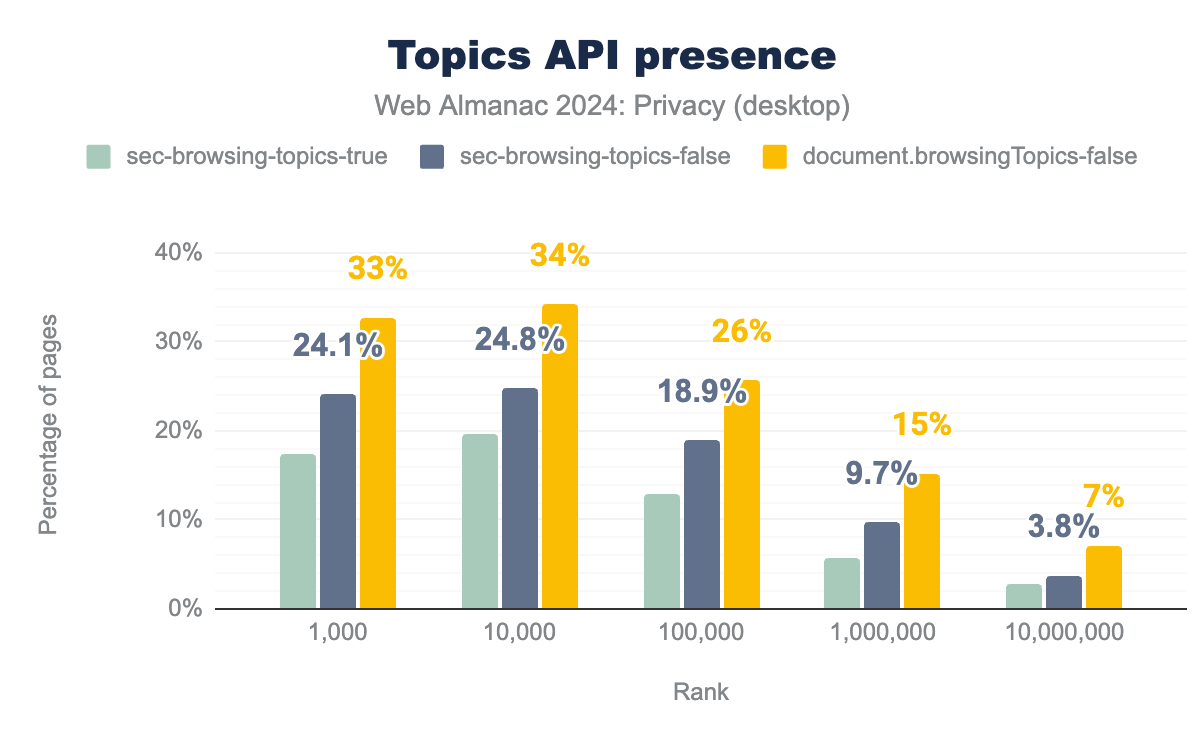
Since this API can be deployed both through the HTTP headers and JavaScript, we measure the adoption of the Topics API across both of these axes. We observe JavaScript-based presence (document.browsingTopics) at 7% of pages, to be more widespread than header-based presence (sec-browsing-topics) at ~4% pages.
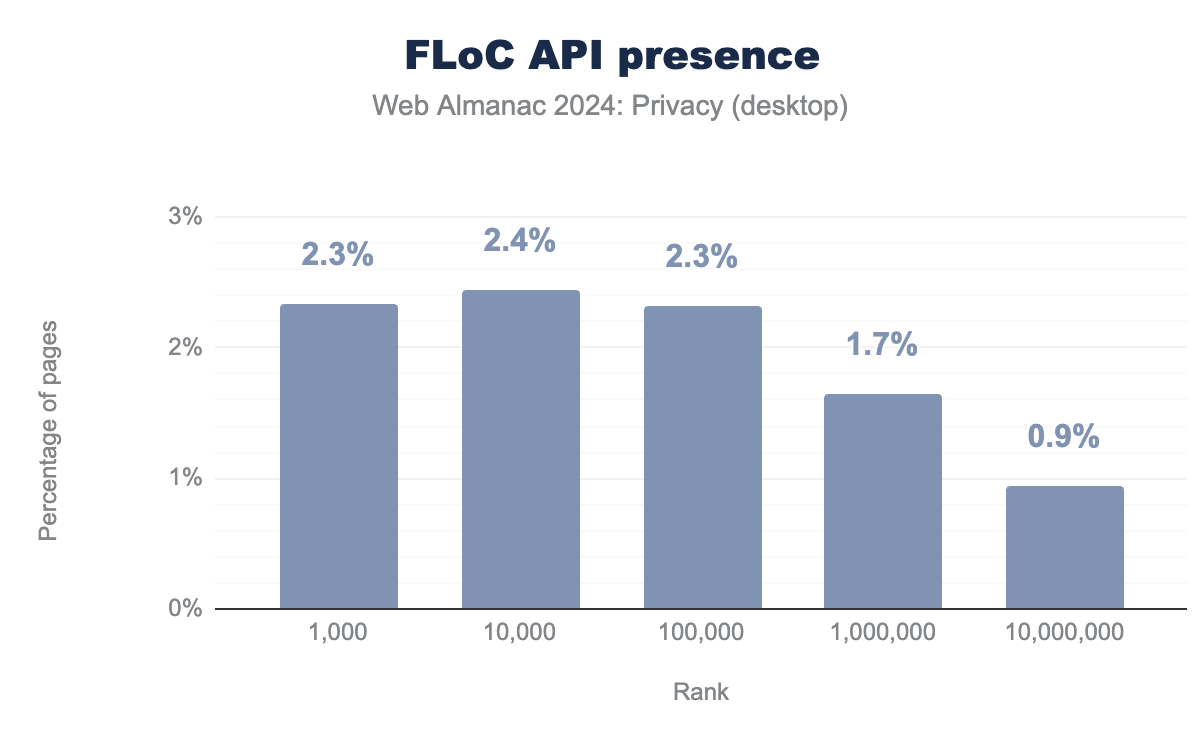
Surprisingly, we also note that the Federated Learning of Cohorts API (FLoC)—a precursor proposal to Topics API, despite being deprecated due to several privacy issues, is still present on a considerable amount of pages. While Topics API improves the status quo, prior research has shown that monitoring the topics returned by the user’s browser over a period of time can aid in reidentification of users.
Protected Audience API
The Protected Audience API enables on-device auctions by the browser, to choose relevant ads from websites the user has previously visited. It eliminates the need for privacy-invasive data collection and pervasive tracking practices that are otherwise employed for remarketing and targeted advertising. This ensures that advertisers can serve relevant ads without needing to track users across sites.
-API-Presence.png)
Amongst different method calls available for the Protected Audience API, we note that navigator.joinAdInterestGroup() is used the most by third-party services—63% of top 10 million websites.
This API provides an ability to a third-party service to direct the browser to add an interest group to the browser’s membership list for the visiting user. Recent research (Calderonio et al., Long and Evans) has discovered various privacy flaws with respect to the Protected Audience API. For example, third-party trackers can potentially link the interest groups of the users to an actual user using side-channels and track them across sites. Possibility of colluding entities further alleviate the associated privacy risk.
Attribution Reporting API
Attribution Reporting API (ARA) introduces a privacy-preserving mechanism for measuring ad conversions in Google Chrome. Its purpose is to enable attribution measurement by providing a capability to register attribution source and trigger on publisher and advertiser websites, respectively. Chrome records every conversion, and generates a differentially private report that is sent to authorized sources with a delay, preventing cross-site linking of the users. This mechanism works through the use of specific HTTP headers:
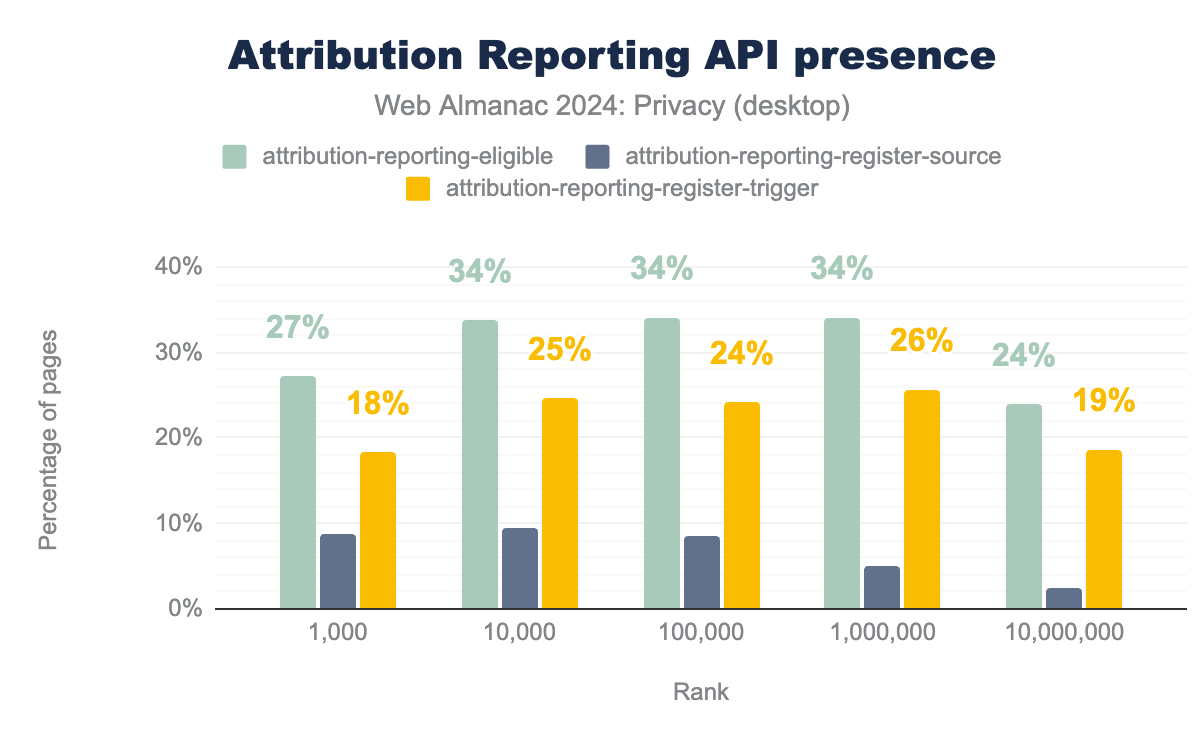
attribution-reporting-eligible: This header signals that a particular request’s response is eligible for attribution reporting.attribution-reporting-register-source: Used to register attribution sources when displaying an advertiser’s ad on publishers.attribution-reporting-register-trigger: Used on the advertiser’s website to register triggers that measure conversions when users interact with ads.
From our analysis, we observe that twice as many third parties are registering triggers compared to those registering sources. This trend indicates a higher focus on measuring conversions as compared to tracking the initial ad display events.
Since most of the popular browsers are competing with each other in the space of privacy preserving attribution with proposals like ARA for Chrome, Private Click Measurement (PCM) for Safari, and Interoperable Private Attribution (IPA) by Mozilla and Meta, we analyze ARA in more detail. We look at registrations of advertising destinations on different websites.
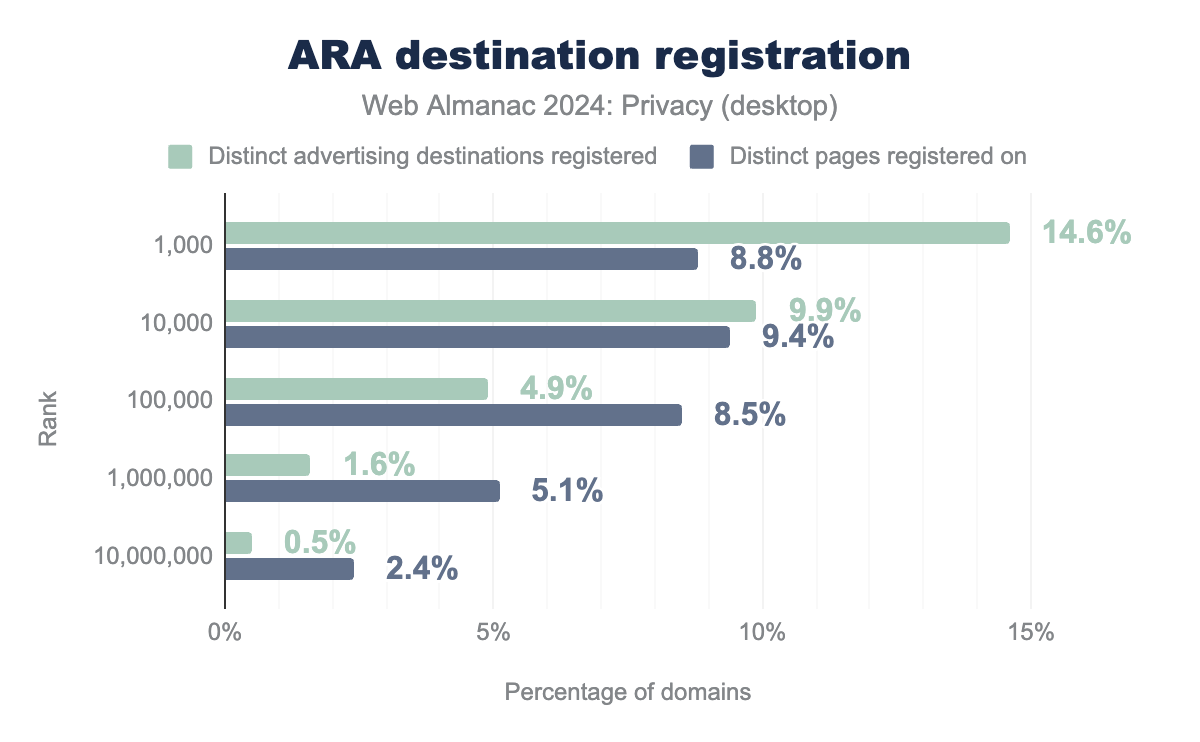
We observe that 14.6% distinct advertisers are using ARA to register themselves using attribution-reporting-register-trigger header on 8.8% distinct publishers on the top 1,000 websites. In total, we observe 1.6% (0.5%) distinct advertisers have adopted ARA across 5.1% (2.4%) publishers in top million (top 10 million) websites. This shows that not many publishers have adopted ARA as compared to the advertiser adoption—preparing themselves for the post-cookie world where they will need to rely on ARA to attribute user conversions to ad clicks.
Related Websites Sets
Related Website Sets allow websites from the same owner to share cookies among themselves.The creation and submission of a Related Website Set is done at the moment through opening a pull request on a GitHub repository that the Google project contributors check and merge if deemed valid. Websites that belong to the same related website set must also indicate it by placing a corresponding file at the .well-known URI .well-known/related-website-set.json.
Chrome ships with a pre-loaded file containing related website sets validated by the Chrome team. At the moment of writing (version 2024.8.10.0), there are 64 distinct related website sets. Each related website set contains a primary domain and a list of other domains related to the primary one under one of the following attributes: associatedSites, servicesSites, and/or ccTLDs. These 64 primary domains are each associated with secondary domains as part of their set: 60 sets contain associatedSites, 11 servicesSites, and 7 ccTLDs—see the Cookies chapter for more results.
Law and policy
With increasing scrutiny against online tracking, there have been numerous new laws and regulations passed to make online advertisers and trackers more accountable. In this section we look at the impact these regulations have had on privacy.
Consent dialogs
With the introduction of privacy regulations like the General Data Protection Regulation (GDPR) in the European Union and California Consumer Privacy Act (CCPA), websites require user consent to collect, share, and process user data—for example, collection and usage of third-party tracking cookies. This has led to the widespread use of cookie consent dialogs, which notify users about the data collection practices and allow them to accept, reject, or customize their consent.
These consent dialogs have become a ubiquitous feature across the web, but their effectiveness in truly protecting user privacy is debated. Many websites use “dark patterns” to nudge users into accepting tracking, while others present complex options that can overwhelm non-technical users. The Interactive Advertising Bureau (IAB) Europe introduced the Transparency and Consent Framework (TCF) to standardize the process of obtaining consent for targeted advertising. The IAB consent dialog is used by many websites and ad tech companies to comply with GDPR and other privacy laws while continuing to serve personalized ads. The framework is designed to provide transparency into how user data is processed and to give users the ability to grant or withhold consent for different purposes, such as personalized ads, analytics, or content delivery.
Our findings show that the TCF, along with other privacy frameworks, is widely implemented as publishers seek to comply with data protection laws like GDPR and CCPA. We would like to note here that our measurement is USA-based, and according to TCF, no consent banner is required for non-EU visits. Therefore, this can result in smaller than actual measurements of TCF usage.
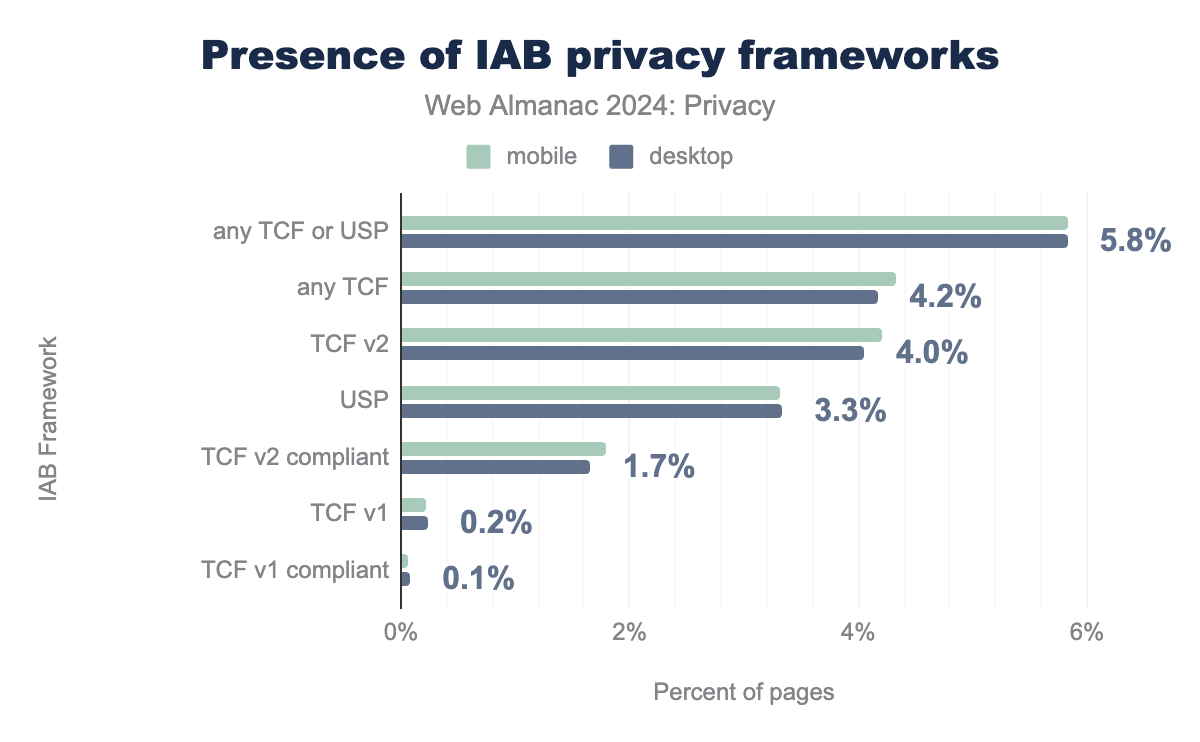
The 2024 data reveals a shift in the privacy landscape compared to 2022. Firstly, the overall prevalence of IAB frameworks has increased. In 2022, the broadest IAB presence (“IAB all”) was found on 4.4% of pages (desktop and mobile combined). In 2024, any TCF or USP framework appears on 5.8% of home pages. This suggests wider adoption of privacy standards, potentially driven by increased regulatory scrutiny and user awareness.
Examining individual frameworks, TCF usage (any version) appears on 4.2% of pages, while USP stands alone on 3.3% of pages. 4.0% of pages use the latest version of TCF (v2), which also makes it the most prevalent version. TCF v2 with compliant setup (presence of vendor consent configuration) appears on a smaller subset, 1.7% of pages. The older TCF v1, which predates GDPR enforcement, is negligible at 0.2%.
Interestingly, while overall IAB framework usage is up, USP adoption has remained relatively stable, hovering around 3.4% in 2022 and 3.3% in 2024. This suggests that the overall growth in privacy framework adoption is primarily driven by increased TCF usage, specifically TCF v2.
Finally, the shift from TCF v1 to TCF v2 is evident. While TCF v1 in 2022 had some measurable presence (0.3% on mobile), it is nearly obsolete in 2024 at 0.2%. TCF v2 adoption has grown considerably (1.9% to 4%), further indicating a movement toward newer, GDPR-aligned consent mechanisms. However, full TCF v2 compliance remains relatively low, highlighting the ongoing challenge of implementing its complex requirements fully.
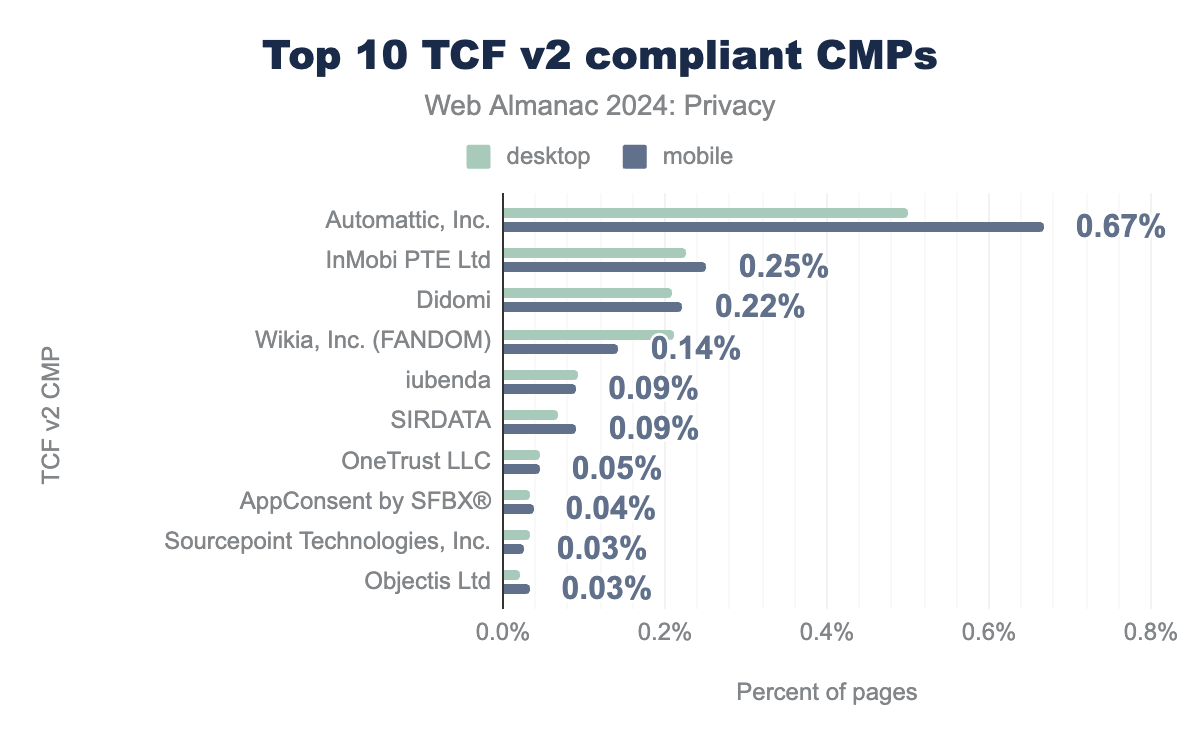
Our analysis of Consent Management Platform (CMP) usage within the TCF v2 ecosystem shows that Automattic, Inc. leads in adoption, appearing on 0.67% of pages, followed by InMobi PTE Ltd at 0.25% and Didomi at 0.22%. This suggests that certain CMPs have become trusted for managing consent effectively, though the relatively low adoption rates imply that many sites may still depend on in-house solutions or less widely recognized CMPs.
Do Not Track
Do Not Track (DNT) was a browser-based privacy initiative introduced in the early 2010s. It allowed users to set a browser preference indicating that they did not wish to be tracked by websites. However, DNT failed to gain widespread adoption, largely because it was voluntary and lacked enforcement mechanisms.
While DNT was a pioneering idea in user privacy, it ultimately became obsolete as major advertisers and trackers chose to ignore DNT requests, and it was not enshrined in any legal frameworks. Despite being obsolete, our analysis shows that 19.8% of desktop websites, and 18.4% of mobile websites still support a DNT signal. It’s crucial to point out here that while these sites may check for the DNT signal, how well these sites adhere to and comply with the signal is unclear.
Global Privacy Control
Global Privacy Control (GPC) is a more recent initiative designed to give users a simple, browser-based mechanism to communicate their privacy preferences to websites, similar to DNT. However, unlike DNT, GPC is backed by legal regulations like the CCPA (California Consumer Privacy Act).
GPC allows users to signal that they do not want their data to be sold or shared with third parties, and companies are legally obligated to respect this signal under certain laws. Major browsers and privacy-focused extensions support GPC, and it is gaining traction as a more effective tool for user privacy.
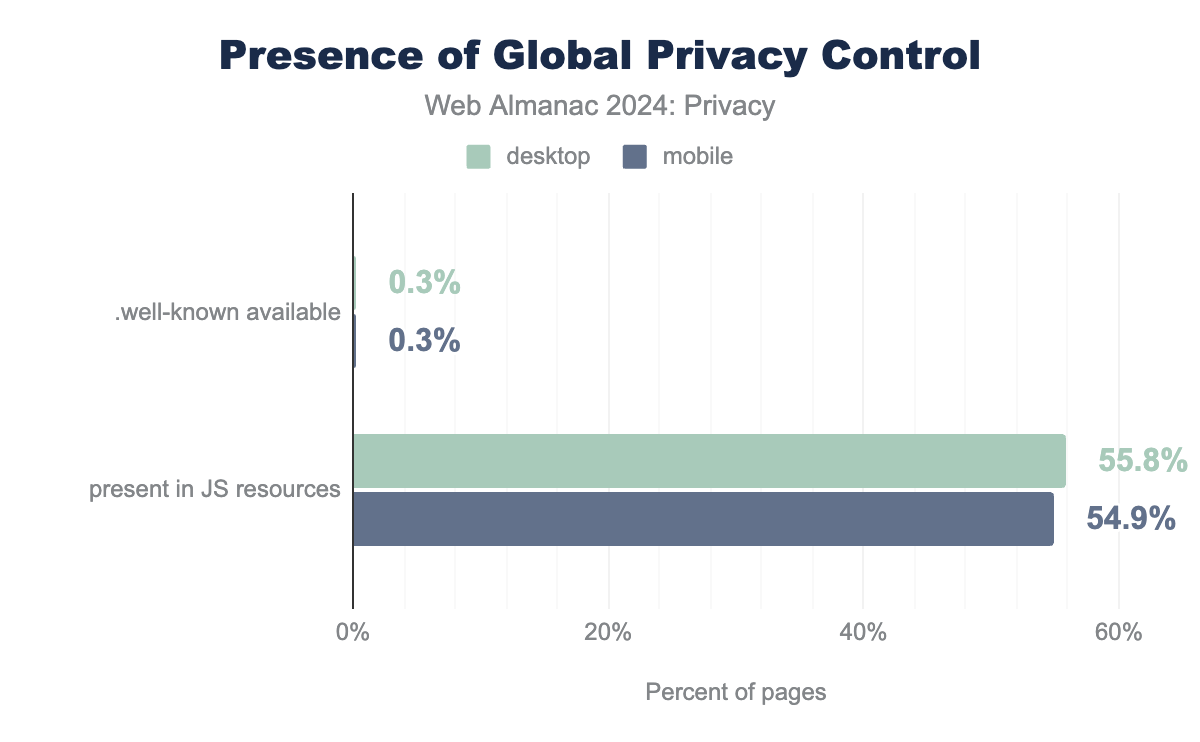
present in JS resources: This indicates that GPC was detected within the JavaScript code executed by the web page, suggesting active implementation or recognition of the signal by the site. This method reveals a high prevalence of GPC, with about 55.8% on desktop and 54.9% on mobile. .well-known available: This refers to a specific resource being available at a particular origin, which means GPC is supported but not necessarily abided by. The prevalence using this method is significantly lower: around 0.3% for desktop and mobile.Analysis shows that on 55.8% of desktop sites and 54.9% of mobile sites the GPC signal can be accessed through JavaScript, which is significantly higher than the DNT signal. Another optional requirement of GPC is a well-known URL which resides at the /.well-known/gpc.json endpoint (relative to the website’s origin server URL). This resource is meant to indicate the website’s awareness and support of GPC, but at the same time it doesn’t guarantee that it abides by GPC. In our measurements, we find that only 0.2% of mobile and desktop sites have an accessible well-known endpoint.
California Consumer Privacy Act
The California Consumer Privacy Act (CCPA), enacted in 2018, is one of the most significant privacy laws passed in the United States. It grants California residents rights over their personal data, including the right to know what data is being collected, the right to request deletion of their data, and the right to opt out of the sale of their data. CCPA has had a profound impact on the web, as companies across the globe must comply if they collect or process data from California residents. This has led to the introduction of “Do Not Sell My Info” links on many websites and increased awareness around data privacy in the U.S.
Under the law, any business that does business in California and meets certain size thresholds must provide a way for users to opt-out of the selling or sharing of their personal information. To comply with the law, the California Attorney General’s office recommends placing a link on the business’ home page with the text “Do Not Sell My Personal Information” and a standardized icon. Building on prior work that identified a common set of CCPA link phrases, we conducted an analysis of the prevalence of these links across sites according to their popularity level.
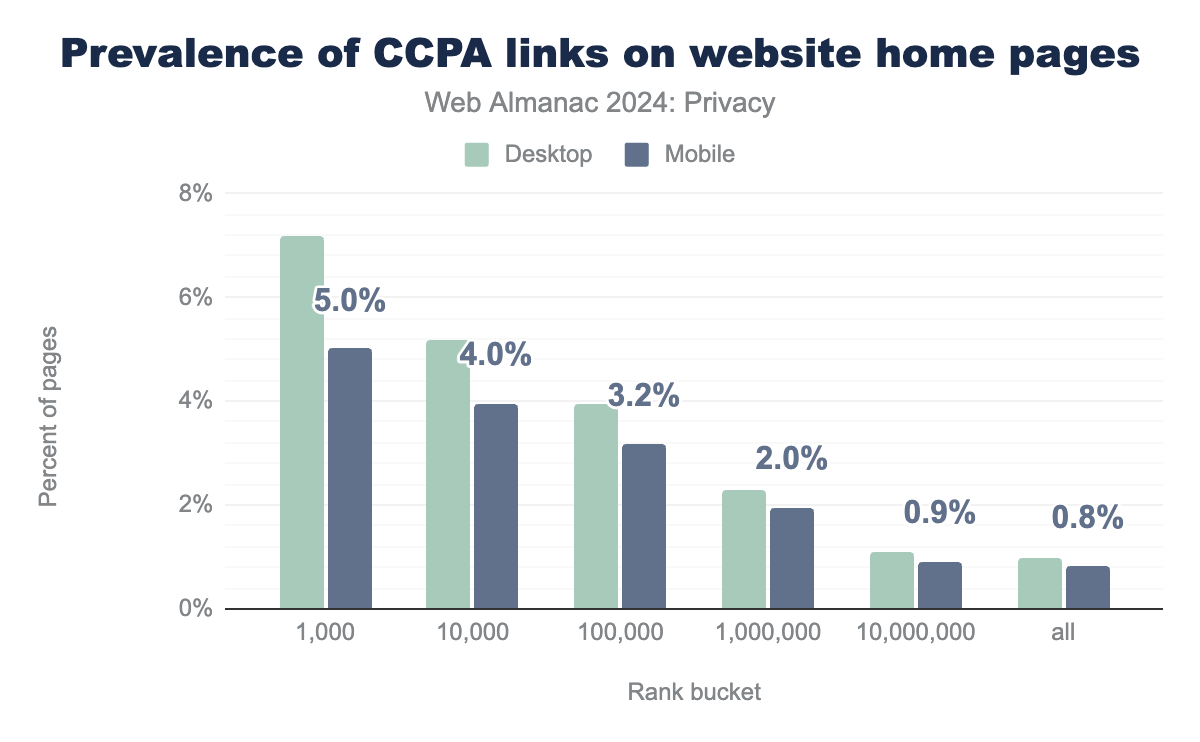
Overall, we note that only 0.96% of websites CCPA links. We also note that more websites with higher ranks include CCPA links, as compared to websites with lower ranks. Higher rank websites are more likely to have a CCPA link, either because they are more likely to meet the thresholds to be covered under the CCPA, or simply because they are more aware of the requirements.
However, the rate of links among the top 1,000 websites is only 7.19%, which is quite low. While it is impossible to know how many of these sites meet the requirements to be covered under the CCPA, it is likely that many top ranked websites at least meet the revenue threshold, so unless they take steps to actively block California users, they would appear to be covered.
One limitation of our crawl is that it is geographically distributed, and as such we cannot accurately account for websites that dynamically show a CCPA link only to visitors in California. Therefore, our results likely underestimate the prevalence of these links. However, it is important to note that, as per prior research conducted in 2022, only 17% of CCPA links were dynamically hidden.
Finally, we examine which phrasing is most commonly used in CCPA links.
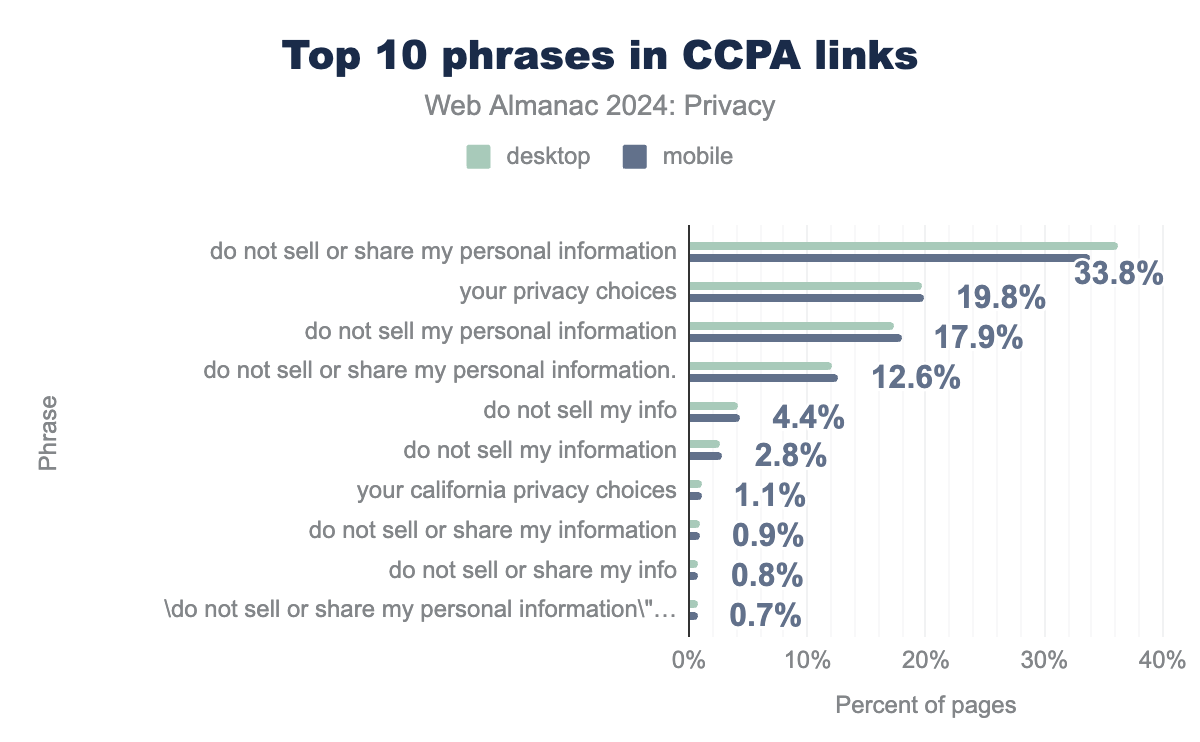
The majority of sites use variants of the phrase recommended under CCPA , “do not sell my personal information”. However, a significant number of sites also contain links titled “your privacy choices”, whose implication is less clear. This may make it more difficult for users to opt-out on these sites.
Conclusion
We find that online tracking is not just prevalent but almost ubiquitous, with 95% of desktop and 94% of mobile websites containing at least one tracker. Major companies like Google and Facebook dominate this landscape with presence on 68% and 23% of the web pages, respectively. We also observe that trackers utilize both stateful methods (like cookies and local storage) and stateless methods (like browser fingerprinting) to track users across the internet.
Trackers are continually developing sophisticated techniques to bypass privacy-enhancing efforts. Notably, methods such as CNAME cloaking and bounce tracking have emerged, allowing trackers to disguise themselves as first-party entities and exploit browser functionalities to persist in their tracking efforts.
The chapter also assesses the adoption of browser policies designed to enhance user privacy, such as User-Agent Client Hints and Referrer Policy. While there is a gradual increase in the implementation of these features from 2022 (when this analysis was last conducted), their adoption remains uneven across the web. Additionally, the introduction of Privacy Sandbox proposals like the Topics API, Protected Audience API, and Attribution Reporting API signifies a positive shift towards privacy-preserving technologies in online advertising.
On the legal front, regulations like the GDPR and CCPA have prompted a surge in consent dialogues and frameworks like the IAB’s Transparency and Consent Framework. Yet, the effectiveness of these measures is questionable due to limited adoption.








{kind=link}
{kind=link}